2019. 05. 09.
조회수 3307
Node 서버로 Slack 메신저 자동화하기
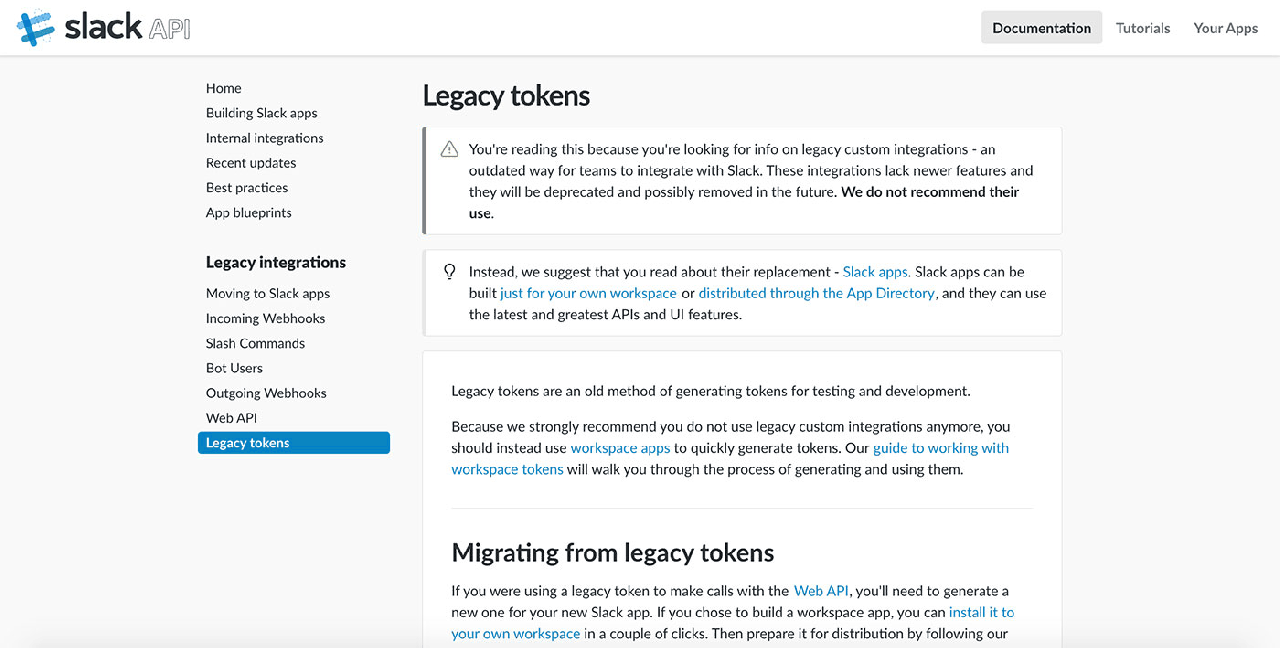
Overview백엔드 업무를 하면 데이터 요청과 CS문의를 자주 받습니다. 날짜만 다를 뿐 같은 유형의 문의가 대부분이죠. 결국 반복적인 업무를 효율적으로 처리할 수 있는 방법을 고민했고, 사내 메신저로 사용하는 Slack의 몇 가지 API를 사용하기로 했습니다.1. 알림봇 만들기비즈니스 로직을 만들다 보면 정해진 시간에 맞춰 작업을 해야 하는 경우가 발생합니다. Slack 메신저에 로그온한 상태에서 스케줄러를 이용해 지정한 시간에 Slack 메세지를 전송해보겠습니다.1)Slack API 유저토큰 받기Slack API에 사용할 해당 계정의 토큰을 받아야 합니다. Slack 가입 절차 및 채널 생성은 생략하겠습니다.https://api.slack.com/custom-integrations/legacy-tokens 접속합니다.Legacy tokens 메뉴에서 아래로 스크롤을 내려 토큰 생성버튼을 누릅니다.계정 패스워드를 입력하여 확인하면 토큰을 생성할 수 있습니다.생성된 토큰을 복사하여 저장합니다.2)Node.js를 이용한 알림봇 구현2-1.Node.js 설치Node.js 다운로드 해당 사이트에서 운영체제 환경에 맞는 파일을 다운받아 설치2-2.프로젝트 생성해당 프로젝트 폴더로 이동 후 명령어 실행$ npm init --yes // package.json 파일 생성2-3.Slack 연동2-3-1. slack-node 모듈 설치$ npm install slack-node --save2-3-2. 유저토큰을 이용하여 해당채널에 메세지 전송const Slack = require('slack-node'); // 슬랙 모듈 사용 apiToken = "발급받은 유저토큰"; const slack = new Slack(apiToken); const send = async(message) => { slack.api('chat.postMessage', { username: 'dev-test', // 슬랙에 표시될 봇이름 text:message, channel:'#general' // 전송될 채널 및 유저 }, function(err, response){ console.log(response); }); } send('메세지 내용'); 지정한 채널에 메시지가 발송됩니다. 하지만 이와 같은 방법은 유저 토큰이 공개 코드에 노출되기 때문에 보안이 취약할 수 있습니다. 유저 토큰이 필요 없어도 해당 채널에 URL을 생성하는 WebHooks API를 이용하여 메시지를 전송해보겠습니다.3) Incoming WebHooks APIWebHooks는 유저 토큰 대신 Webhook URL을 생성해 HTTP 통신으로 Slack 메세지를 전송할 수 있습니다. 다양한 메시지 형식을 지원하고 게시할 사용자 이름 및 아이콘 등을 통합적으로 관리할 수 있는 장점을 가지고 있습니다.3-2. Webhook URL 생성하기Slack 해당채널에서 Add an app 클릭검색필터에 WebHooks 검색Incoming WebHooks 추가채널 선택 후 Incoming WebHooks 생성생성된 Webhook URL 복사하여 저장해당채널에 생성되었는지 확인봇이름 및 아이콘등 기본 설정 변경하여 저장curl 사용 예제$ curl -s -d "payload={'text':'메세지 내용'}" "Webhook URL"Webhook URL 사용 중인 모든 메시지는 통합적으로 기본 설정이 변경된 걸 확인할 수 있습니다.다양한 형식의 메세지를 전송해보겠습니다.const Slack = require('slack-node'); // 슬랙 모듈 사용 const webhookUri = "Webhook URL"; // Webhook URL const slack = new Slack(); slack.setWebhook(webhookUri); const send = async(message) => { slack.webhook({ text:"인터넷 검색 포털 사이트", attachments:[ { fallback:"링크주소: ", pretext:"링크주소: ", color:"#00FFFF", fields:[ { title:"알림", value:"해당링크를 클릭하여 검색해 보세요.", short:false } ] } ] }, function(err, response){ console.log(response); }); } 다양한 형태의 메시지를 전송할 수 있습니다.4) Schedule 연동이제 스케줄러를 이용하여 지정한 시간에 메세지를 전송해보겠습니다.4-1. node-schedule 모듈 설치node-schedule는 Node.js 작업 스케줄러 라이브러리입니다.$ npm install node-schedule --savenode-schedule 코드 작성const schedule = require('node-schedule'); // 스케줄러 모듈 사용 // rule-style 사용 var rule = new schedule.RecurrenceRule(); rule.dayOfWeek = new schedule.Range(3,4); rule.hour = 19; rule.minute = 50; schedule.scheduleJob(rule, function(){ console.log('rule 방식'); }); // cron-style 사용 schedule.scheduleJob('50 19 * * *', function(){ console.log('cron-style 방식'); }); 취향에 맞는 스타일로 사용하면 됩니다.5) 지정 시간에 메세지를 전송하는 알림봇을 작성해보겠습니다.const Slack = require('slack-node'); // 슬랙 모듈 사용 const schedule = require('node-schedule'); // 스케줄러 모듈 사용 const webhookUri = "Webhook URL"; // Webhook URL const slack = new Slack(); slack.setWebhook(webhookUri); const send = async(message) => { slack.webhook({ text:message, attachments:[ { fallback:"구글드라이브: ", pretext:"구글드라이브: ", color:"#00FFFF", fields:[ { title:"[알림]", value:"해당링크로 접속하여 작성해 주세요.", short:false } ] } ] }, function(err, response){ console.log(response); }); } schedule.scheduleJob('5 19 * * *', function(){ send('업무보고 보내셨나요?'); }); 업무보고 시간을 미리 알려주는 알림봇2. 대화봇 만들기업무 문서는 주로 구글 독스와 같은 온라인 문서로 관리하고 있습니다. 하지만 매번 구글 드라이브에서 문서를 찾는 건 정말 귀찮은 일입니다. 번거로운 건 딱 질색입니다. Slack API를 이용해 관련된 키워드를 입력하면 링크 주소를 바로 받을 수 있는 대화봇을 만들어 보겠습니다.1) Slack API Bots 토큰 받기Slack API에 사용될 Bots 토큰을 받아야 합니다.https://{App Name}.slack.com/apps 에 접속합니다.Bots 추가Bots Api 토큰을 복사해 저장합니다.설정한 봇이름으로 Apps 영역에 자동으로 추가됩니다.2) 구글독스 대화봇 코드 작성2-1. botkit 모듈 설치$ npm install botkit --save2-2. 코드 작성const botkit = require('botkit'); // 봇 모듈 사용 const Slack = require('slack-node'); // 슬랙 모듈 사용 const controller = botkit.slackbot({ debug: false, log: true }); const botScope = [ 'direct_message', 'direct_mention', 'mention' ]; controller.hears(['업무보고'], botScope, (bot, message) => { bot.reply(message, '업무보고 링크주소'); }); controller.hears(['가이드', 'guide', '튜토리얼'], botScope, (bot, message) => { bot.reply(message, '가이드 링크주소'); }); controller.hears(['api', '명세서'], botScope, (bot, message) => { bot.reply(message, 'api명세서 링크주소'); }); controller.hears(['일정', '일정관리'], botScope, (bot, message) => { bot.reply(message, '일정관리 링크주소'); }); controller.hears(['비품', '비품정리'], botScope, (bot, message) => { bot.reply(message, '비품관리 링크주소'); }); controller.spawn({ token: '발급받은 봇 토큰' }).startRTM(); 지정한 키워드를 입력하면 해당 링크가 수신 됩니다.3) 데이터문의 대화봇 코드 작성데이터 요청 시 결과 데이터를 보내주는 대화봇을 만들어 보겠습니다. 일단 먼저 데이터문의 전용 Bots을 생성합니다.3-1. Python 연동 요청한 데이터는 Mysql 데이터를 조회해서 전송합니다. 그러면 Mysql 을 연동해야겠죠? Node.js에서도 직접 mysql 연결할 수 있지만, 기존 프로젝트가 Python으로 구현되어 있어 Python을 실행해 필요한 데이터를 추출해보겠습니다.3-2. python-shell 모듈 설치Node.js에서 Python 실행가능하도록 모듈을 설치$ npm install python-shell --save3-3. Mysql Sample Table3-4. 회원테이블에 저장된 가입일시 기준으로 몇일전에 가입한 회원을 추출하여 전송하는 코드 작성해 보겠습니다.const botkit = require('botkit'); // 봇 모듈 사용 const Slack = require('slack-node'); // 슬랙 모듈 사용 const ps = require('python-shell'); // 파이썬 쉘 모듈 사용 // 몇일 전 날짜 구하기 function getDaysAgo(dayNo = 0) { let nowDate = new Date(); let tempDate = nowDate.getTime() - (dayNo * 24 * 60 * 60 * 1000); nowDate.setTime(tempDate); let getYear = nowDate.getFullYear(); let getMonth = nowDate.getMonth() + 1; let getDay = nowDate.getDate(); if (getMonth < 10 xss=removed xss=removed xss=removed xss=removed xss=removed xss=removed xss=removed xss=removed xss=removed xss=removed xss=removed xss=removed xss=removed xss=removed xss=removed> 3-5. Python 코드 작성 # -*- coding: utf-8 -*- import sys import pymysql // mysql 접속 db = pymysql.connect('hostname', user='', passwd='', db='', charset='utf8') cursor_db = db.cursor() exe_query = "SELECT MEMBER_NAME FROM MEMBER_INFO WHERE MEMBER_REGIST_DETE >= '{}' ORDER BY MEMBER_NO ASC ".format(sys.argv[1]) cursor_db.execute(exe_query) all_rows = cursor_db.fetchall() for idx, row in enumerate(all_rows): print(row[0]) 지정한 며칠 전에 가입한 회원 이름이 전송됩니다. 로그도 정상적으로 출력됩니다. 3. Node.js 프로세스 관리를 위한 pm2 모듈 설치 Node.js 는 비동기 I/O를 지원하며 단일 스레드로 동작하는 서버입니다. 비동기식 방식이지만 처리하는 Event Loop는 단일 스레드로 이루어져 있어 처리 작업이 오래 걸리면 전체 서버에 영향을 줍니다. 그래서 pm2를 이용해 프로세스별로 상태를 관리해야 합니다. 1) pm2 모듈 설치$ npm install pm2 -g2) 자주사용하는 pm2 명령어 pm2 list -> 실행중인 프로세스 확인pm2 start {node 파일} -> 시작pm2 stop {id or App name} -> 중지pm2 delete {id or App name} -> 삭제pm2 show {id or App name} -> 상세정보pm2 restart {id or App name} -> 재시작pm2 kill -> pm2 종료pm2 logs {id} -> id 앱의 로그 확인 3) pm2 실행화면$ pm2 start bot.js 프로세스별로 앱 이름, 버전, 상태, cpu 및 memory 사용량이 표시됩니다.$ pm2 show 0 해당 프로세스의 상세 정보를 확인할 수 있습니다. Conclusion 지금까지 Node.js 로 유용한 Slack 메신져 API를 알아봤습니다. 반복적인 업무를 하나씩 줄이다 보면 분명 일의 능률을 높아집니다. 하지만 무분별한 자동화는 서버의 부하를 증가시키기 때문에 꼭 필요한지 확인하고 선택하길 바랍니다. 오늘은 여기까지 글곽정섭 과장 | R&D 개발1팀[email protected]브랜디, 오직 예쁜 옷만