들어가며
지난 글에 이어서 이번에는 코인원에서 Prometheus를 어떻게 활용하는지에 대해서 이야기해보고자 합니다. 주로 Prometheus의 데이터들을 grafana에서 어떻게 활용하는지에 대한 이야기가 될 듯합니다.

리소스 상태를 한눈에 볼 수 있는 대시보드를 만들자!
코인원의 차세대 엔진 프로젝트가 마무리 단계에 접어들며 저희는 성능에 대한 테스트를 진행해야 했었습니다. 우선은 가장 기본적인 CPU, Memory, Network에 대한 usage를 확인하는 것으로 범위를 잡았고, Prometheus의 Web UI Console에서 관련 metric 정보들이 있는지 확인하였습니다.
Web UI Console을 사용해보신 분들은 아시겠지만, Prometheus의 metric naming은 체계적으로 잘 정의되어 있어서 query 입력창을 통해 손쉽게 확인이 가능했습니다.

최종적으로는 아래 query로 usage metric을 산출하였고, 이를 grafana의 대시보드에 구성하였습니다.
Prometheus의 query (PromQL)의 기본적인 사용법과 function의 종류, 예제들은 Prometheus 공식 문서를 참고하였습니다.
Query에서 변수 처리된 부분은 grafana에서 variable로 지정된 값으로 치환이 됩니다.
다만, pod는 매번 생성과 삭제가 반복되기에 지정된 pod_name 설정이 어렵습니다. 그래서 kube_deployment_metadata_generation query를 이용하여 grafana의 variable에 label_values로 지정을 해줍니다.
Usage metric에 대한 구성이 완료된 이후에는 해당 대시보드를 대형 모니터에 띄워서 모든 Application 대한 리소스 사용량 변화 추이를 한눈에 볼 수 있게 구성하였습니다.
다만, 이때는 모니터의 화면 사이즈에 대한 제약이 있어서 꼭 필요한 metric만 선별해야 했습니다.
그래서 위의 Usage 외에 Pod의 수량과 상태 정보, Node의 Memory 및 Disk Usage와 해당 Node에서 실행되는 Pod 개수, Uptime 정보 정도만 선별하여 아래 query로 Prometheus에서 산출하였습니다.
최종적으로 Pod와 Node의 grafana 대시보드를 구성한 모습은 아래와 같습니다.
상단의 드롭다운 박스에서 kubernetes의 namespace와 deploy 된 pod를 선택하면, row 단위로 그래프가 나타납니다.

Node 또한 해당 node를 선택하면 row 단위로 그래프가 나타나도록 대시보드를 구성하였습니다.

장애 증상 탐지와 Alert Notification
한 번은 저희 사이트 기능이 간헐적으로 문제가 생기는 이슈가 발생했습니다. kubectl에서 확인했을 때, 해당 서비스의 Pod들은 멀쩡히 running 상태로 운영이 되고 있었습니다.
그래서 Prometheus의 최근 데이터를 확인해보니, 아래와 같이 특정 Pod의 Memory 사용률이 급격히 올라가는 것을 확인하게 되었습니다.
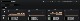
그런데 해당 이슈를 수정하고, 검증하는데는 많은 시간이 필요로 하다는 피드백을 받게 되었습니다.
문제는 저희의 서비스가 24시간으로 운영이 되고 있는데, 어느 순간에 해당 문제가 발생할지도 알 수가 없었습니다.
한가지 확실한 것은 평상시에는 Memory의 사용량이 일정하다는 것이었습니다. 그래서 Grafana에서 해당 Rule을 아래와 같이 만들고, 저희 Slack으로 Notification을 받을 수 있도록 지정했습니다.
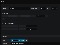
참고로 Grafana를 세팅할 때 한가지 문제점이 있는데, Alert를 추가하고자 하는 대시보드의 Prometheus Query에서 variable을 사용하게 되면 Alert를 생성할 수가 없습니다.

그래서 저희는 모니터링 Alert 전용 대시보드를 별도로 만들고, 해당 Prometheus Query는 variable 지정된 부분을 고정값으로 넣어 해결을 했습니다.
물론 Prometheus-alertmanager를 이용해서도 구성이 가능합니다. 저희의 경우에는 Grafana에서 언제 문제가 발생했고 알람을 보냈으며, 해결되었는지 확인이 되어 좋았습니다.

Worker Node 현황을 한눈에 보자!
kubernetes의 운영 초기에 Pod를 Deploy 하다 보면 Worker Node의 CPU나 Memory의 resource가 부족하여 pending으로 멈춰 있던 경우가 종종 있었습니다.
그래서 Node에 대한 리소스 현황을 한눈에 볼 수 있는 대시보드가 있었으면 좋을 듯하여, 아래와 같이 Grafana에서 하나의 대시보드로 만들어서, 부족한 자원이 발생하면 다른 Node로 배포하던가 Node를 증설하는데 참고하였습니다.

위 metric에 대한 정보는 아래의 prometheus query로 산출을 하였습니다.
위의 query에서 변수 처리 된 부분은 grafana에서 variable로 지정된 값으로 치환이 됩니다. 일부 변수는 화면에서 숨김처리 되었습니다.
Worker node의 전체 현황을 보여주는 대시보드 외에도 개별 worker node에서 어떤 pod가 생성되었고, 얼마만큼의 리소스를 사용하고 있는지도 모니터링할 수 있도록 아래와 같이 대시보드를 만들었습니다.
참고로 해당 대시보드는 위에서 언급된 query들을 응용하여 구성했습니다.

마무리하며
두 편의 글을 통해 실무에서 Prometheus를 활용하는 법을 소개하였습니다.
저희도 아직은 사용 초기 단계라서 어찌 보면 너무 기초적인 내용일 수 있지만, 저희도 처음에는 Prometheus에 대해 아무것도 모르는 상태에서 이것저것 만져가며 저희에게 맞는 것만 간추린 거라 볼 수 있습니다.
또한, 처음 접하시는 분들이 방대한 metric에 바로 손을 놓으시기보다는 기본적인 것들로 하나씩 구성하여, 최종적으로는 자신들에게 맞는 모니터링 시스템을 구축했으면 합니다.

허민, Platform Engineer

 가입하기
가입하기



