
 비트윈에서는 서비스 초기부터 HBase를 주요 데이터베이스로 사용하였습니다. HBase에서도 일반적인 다른 NoSQL처럼 트랜잭션을 제공하지 않습니다. HBase, Cassandra와 MongoDB는 하나의 행 혹은 하나의 Document에 대한 원자적 연산만 제공합니다. 하지만 여러 행에 대한 연산들을 원자적으로 실행할 수 있게 해주는 추상화된 트랜잭션 기능이 없다면 보통의 서비스 개발에 어려움을 겪게 됩니다. 비트윈 개발팀은 이런 문제를 해결하기 위해 노력했으며, 결국 HBase에서 트랜잭션을 제공해주는 라이브러리인 Haeinsa를 구현하여 실제 서비스에 적용하여 성공적으로 운영하고 있습니다. VCNC에서는 Haeinsa를 오픈소스로 공개하고 이번 글에서 이를 소개하고자 합니다.
비트윈에서는 서비스 초기부터 HBase를 주요 데이터베이스로 사용하였습니다. HBase에서도 일반적인 다른 NoSQL처럼 트랜잭션을 제공하지 않습니다. HBase, Cassandra와 MongoDB는 하나의 행 혹은 하나의 Document에 대한 원자적 연산만 제공합니다. 하지만 여러 행에 대한 연산들을 원자적으로 실행할 수 있게 해주는 추상화된 트랜잭션 기능이 없다면 보통의 서비스 개발에 어려움을 겪게 됩니다. 비트윈 개발팀은 이런 문제를 해결하기 위해 노력했으며, 결국 HBase에서 트랜잭션을 제공해주는 라이브러리인 Haeinsa를 구현하여 실제 서비스에 적용하여 성공적으로 운영하고 있습니다. VCNC에서는 Haeinsa를 오픈소스로 공개하고 이번 글에서 이를 소개하고자 합니다.
Haeinsa란 무엇인가?
Haeinsa는 Percolator에서 영감을 받아 만들어진 트랜잭션 라이브러리입니다. HAcid, HBaseSI 등 HBase상에서 구현된 트랜잭션 프로젝트는 몇 개 있었지만, 성능상 큰 문제가 있었습니다. 실제로 서비스에 적용할 수 없었기 때문에 Haeinsa를 구현하게 되었습니다. Haeinsa를 이용하면 다음과 같은 코드를 통해 여러 행에 대한 트랜잭션을 쉽게 사용할 수 있습니다. 아래 예시에는 Put연산만 나와 있지만, 해인사는 Put외에도 Get, Delete, Scan 등 HBase에서 제공하는 일반적인 연산들을 모두 제공합니다.
HaeinsaTransaction tx = tm.begin(); HaeinsaPut put1 = new HaeinsaPut(rowKey1); put1.add(family, qualifier, value1); table.put(tx, put1); HaeinsaPut put2 = new HaeinsaPut(rowKey2); put2.add(family, qualifier, value2); table.put(tx, put2); tx.commit(); Haeinsa의 특징
Haeinsa의 특징을 간략하게 정리하면 다음과 같습니다. 좀 더 자세한 사항들은 Haeinsa 위키를 참고해 주시기 바랍니다.
- ACID: Multi-Row, Multi-Table에 대해 ACID 속성을 모두 만족하는 트랜잭션을 제공합니다.
- Linear Scalability: 트래픽이 늘어나더라도 HBase 노드들만 늘려주면 처리량을 늘릴 수 있습니다.
- Serializability: Snapshot Isolation보다 강력한 Isolation Level인 Serializability를 제공합니다.
- Low Overhead: NoSQL상에서의 트랜잭션을 위한 다른 프로젝트에 비해 오버헤드가 적습니다.
- Fault Tolerant: 서버나 클라이언트가 갑자기 죽더라도 트렌젝션의 무결성에는 아무 영향을 미치지 않습니다.
- Easy Migration: Haeinsa는 HBase를 전혀 건드리지 않고 클라이언트 라이브러리만 이용하여 트랜잭션을 구현합니다. 각 테이블에 Haeinsa 내부적으로 사용하는 Lock Column Family만 추가해주면 기존에 사용하던 HBase 클러스터에도 Haeinsa를 쉽게 적용할 수 있습니다.
- Used in practice: 비트윈에서는 Haeinsa를 이용하여 하루에 3억 건 이상의 트랜잭션을 처리하고 있습니다.
Haeinsa는 오픈소스입니다. 고칠 점이 있다면 언제든지 GitHub에 리포지터리에서 개선에 참여하실 수 있습니다.
Haeinsa의 성능
Haeinsa는 같은 수의 연산을 처리하는 트랜잭션이라도 소수의 Row에 연산이 여러 번 일어나는 경우가 성능상 유리합니다. 다음 몇 가지 성능 테스트 그래프를 통해 Haeinsa의 성능에 대해 알아보겠습니다.
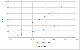
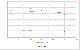
아래 그래프는 3개의 Row에 총 6개의 Write, 3개의 Read연산을 수행한 트랜잭션의 테스트 결과입니다. 두 개의 Row에 3Write, 1Read 연산을 하고, 한 개의 Row에 1Read 연산을 한 것으로, 비트윈에서 가장 많이 일어나는 요청인 메시지 전송에 대해 시뮬레이션한 것입니다. 실제 서비스에서 가장 많이 일어나는 종류의 트랜잭션이라고 생각할 수 있습니다. 그런데 그냥 HBase를 사용하는 것보다 Haeinsa를 이용하는 것이 더 오히려 좋은 성능을 내는 것을 알 수 있습니다. 이는 Haeinsa에서는 커밋 시에만 모든 변경사항을 묶어서 한 번에 반영하기 때문에, 매번 RPC가 일어나는 일반 HBase보다 더 좋은 성능을 내는 것입니다.


아래 그래프는 2개의 Row에 각각 한 개의 Write, 나머지 한 개의 Row에는 한 개의 Read 연산을 하는 트랜잭션에 대해 테스트한 것입니다. 각 Row에 하나의 연산만이 일어나기 때문에 최악의 경우라고 할 수 있습니다. 처리량과 응답시간 모두 그냥 HBase를 사용하는 것보다 2배에서 3배 정도 좋지 않은 것을 알 수 있습니다. 하지만 이 수치는 DynamoDB 상의 트랜잭션과 같은 다른 트랜잭션 라이브러리와 비교한다면 상당히 좋은 수준입니다.
프리젠테이션
Haeinsa에 대한 전반적인 동작 원리와 성능을 소개하는 프리젠테이션입니다. 좀 더 자세히 알고 싶으시다면 아래 프리젠테이션이나 Haeinsa 위키를 참고해주세요.



