인공신경망을 공부하다보면 활성함수(activation function)라는 것을 만나게 됩니다. 대부분의 분들은 처음 공부를 시작할 때, 저와 마찬가지로 활성함수는 그냥 이런 거구나 하신 뒤에 넘어가고 있을 거라 생각합니다. 하지만 딥러닝을 좀더 공부하다보면 어떤 활성함수를 사용했는지, 혹은 사용하지 않았는지로 인해 다양한 문제가 발생하곤 합니다. 특히 요즘 핫한 deep neural network 에서는 활성함수가 어떤 것인가에 따라서 vanishing gradient 문제로 인해 학습의 정도가 달라지기도 합니다. 이러한 이유에서 이번 포스팅에서는 활성함수를 자세히 이해해보도록 하겠습니다.
인공신경망이 사람의 신경구조를 모방하여 만들어졌다는 사실은 다들 알고 계실겁니다. 인공신경망의 가장 기본 개념은 단일 퍼셉트론에서 출발했습니다. 관련된 포스팅에서도 설명했지만 퍼셉트론은 여러 개의 신호가 들어오면 이를 조합하여 다음으로 신호를 보낼지 말지를 결정합니다(0 또는 1). 이것을 발전시킨 feed forward multiple layer neural network는 하나의 단일 뉴런에 여러 신호가 들어오면, 다음 뉴런에 보낼 신호의 강도를 결정하게 됩니다. 즉, 단일 퍼셉트론이 multi layer perceptron으로 발전해나가는 과정에서, 뉴런은 신호의 전달유무가 아닌 전달 강도를 정하게 되었습니다. 이때 전달하는 신호의 세기를 정하는 방법이 활성함수입니다.
많은 분들은 대표적인 활성함수로 sigmoid를 떠올리실 것입니다. 활성함수의 개념을 잡기에는 이만큼 좋은 함수가 없기 때문입니다. 그럼 우선 활성함수의 가장 기본적인 개념을 sigmoid를 통해 알아보도록 하죠. 그 전에 여러분의 이해를 돕기 위해 로지스틱 회귀분석에 대해 먼저 알아보겠습니다.
로지스틱 회귀분석은 generalized linear model입니다. 정확히 말하자면 generalized linear model이라는 큰 개념의 여러 케이스 중 하나라고 볼 수 있겠네요. 로지스틱 회귀분석의 목적은 독립변수의 선형결합으로 종속변수인 ‘어떠한 사건이 발생할 확률’을 알고자 하는 것입니다. 어렵죠..? 쉬운 예시를 하나 들어보겠습니다.
우리는 어떠한 연구를 통해 1일 흡연량과 폐암 발생 여부의 관계를 알고싶습니다. 이때 가장 쉬운 방법은 1일 흡연량{x}과 폐암 발생확률{p(y)}이 선형 관련성이 있다고 보고, 선형 회귀 분석(linear regression)을 시행하는 것입니다. 그 결과, p(y)=0.02x+0.1<math>
담배는 한 갑에 20개비가 들어있고, 3갑이면 60개비가 들어있습니다. 따라서 하루에 담배를 3갑 피우는 사람은 0.02∗60+0.1=1.3<math>
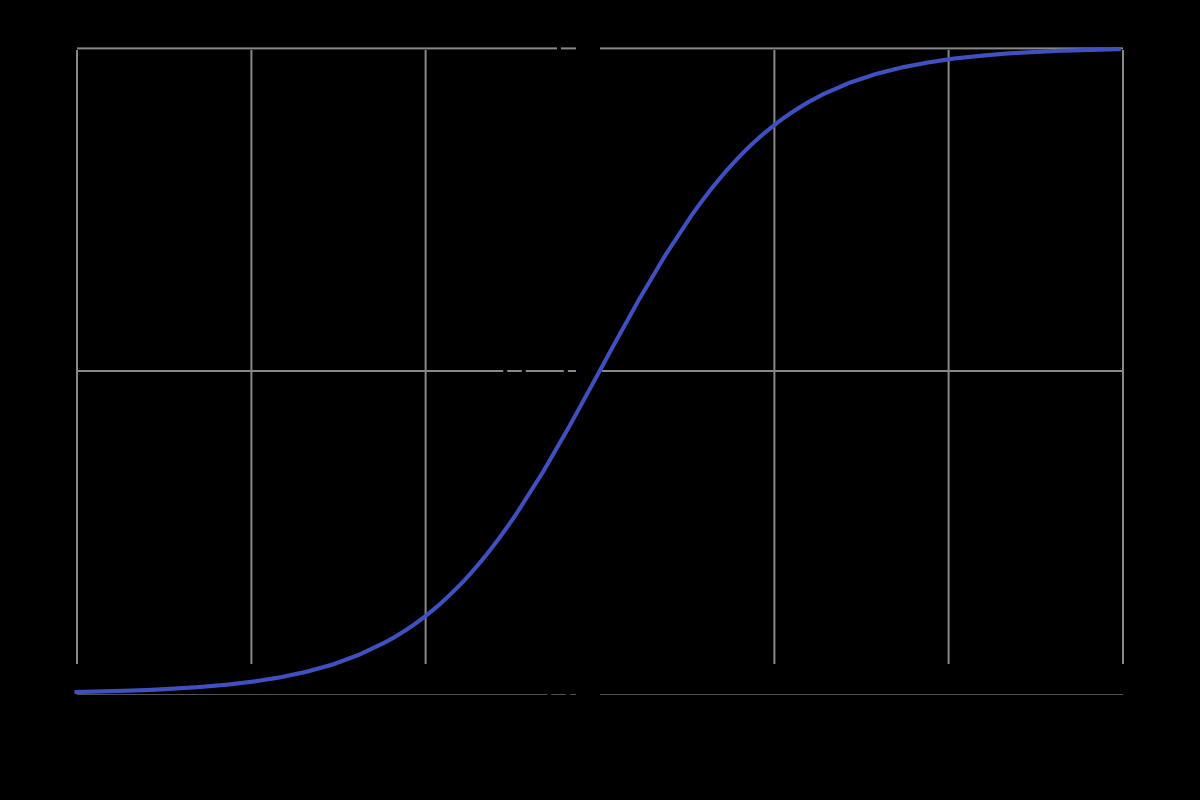
로지스틱 함수는 아래와 같이 생겼습니다.
g(x)=ex1+ex<math>
이것을 연결함수로 적용한 generalized linear model, 즉 logistic regression의 수식은 아래와 같은 형태가 됩니다.
P(y|x)=eβx1+eβx<math>
위 식을 이용하면 비로소 선형이라는 직관적인 성질을 띄면서, 결과값의 범위가 0~1로 제한되어 확률값의 예측에 사용할 수 있는 회귀식이 도출됩니다. 이 때, 위에 사용한 로지스틱 함수가 바로 우리가 활성함수로 사용하는 sigmoid function입니다. 따라서 sigmoid를 활성함수로 사용할 경우, 필연적으로 로지스틱 회귀분석과 관련이 있을 것이라고 예상할 수 있습니다. 둘 간의 관련성을 아래 그림을 통해 알아보겠습니다.
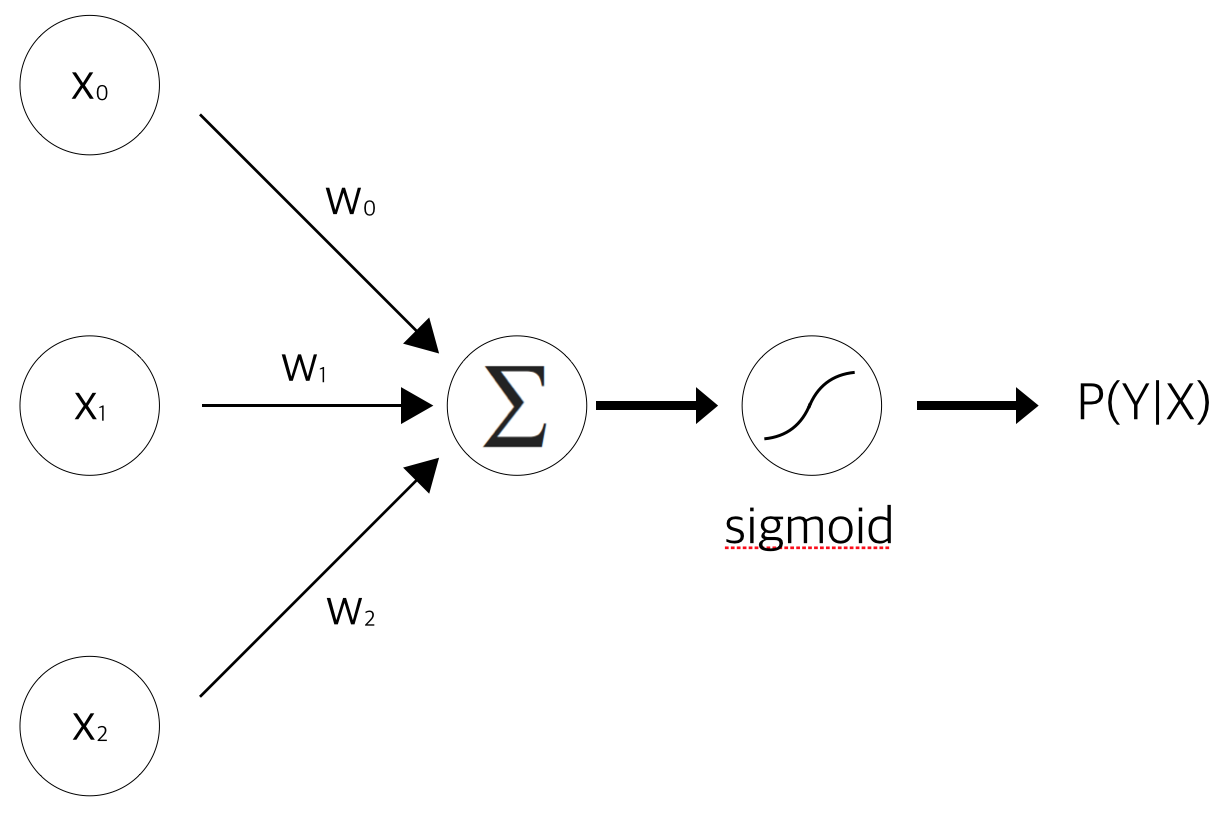
여러분의 이해를 돕고자 hidden layer가 없는 가장 단순한 형태의 feed forward neural network 형태를 그려보았습니다. 위 그림을 수식으로 나타내볼까요?
P(Y|X)=exp(∑2i=0wixi)1+exp(∑2i=0wixi)=11+exp(−∑2i=0wixi)<math>
즉, 위처럼 sigmoid를 활성함수로 사용한 간단한 neural network는 logistic regression과 일치합니다. 물론 계수(weight) 추정 방법은 통계학에서 기존에 행하던 방법과는 차이가 있지만, 결과적으론 비슷한 값이 추정될 것입니다. 우리는 이 그림을 통해 아래와 같은 직관을 얻을 수 있습니다.
이제 눈치 채셨나요? Sigmoid를 활성함수로 사용하는 multi layer perceptron neural network의 hidden layer의 각 뉴런은 로지스틱 회귀분석을 하는 것과 정확히 일치합니다. 따라서 학습 과정에서 각 layer의 weight라는 모수를 학습을 통해 추정하는 것입니다.
그럼 이제 위에서 배운 로지스틱 회귀분석을 mlp에 적용해보겠습니다. 우리는 단층 퍼셉트론 에서 아래와 같은 그림을 보았습니다.
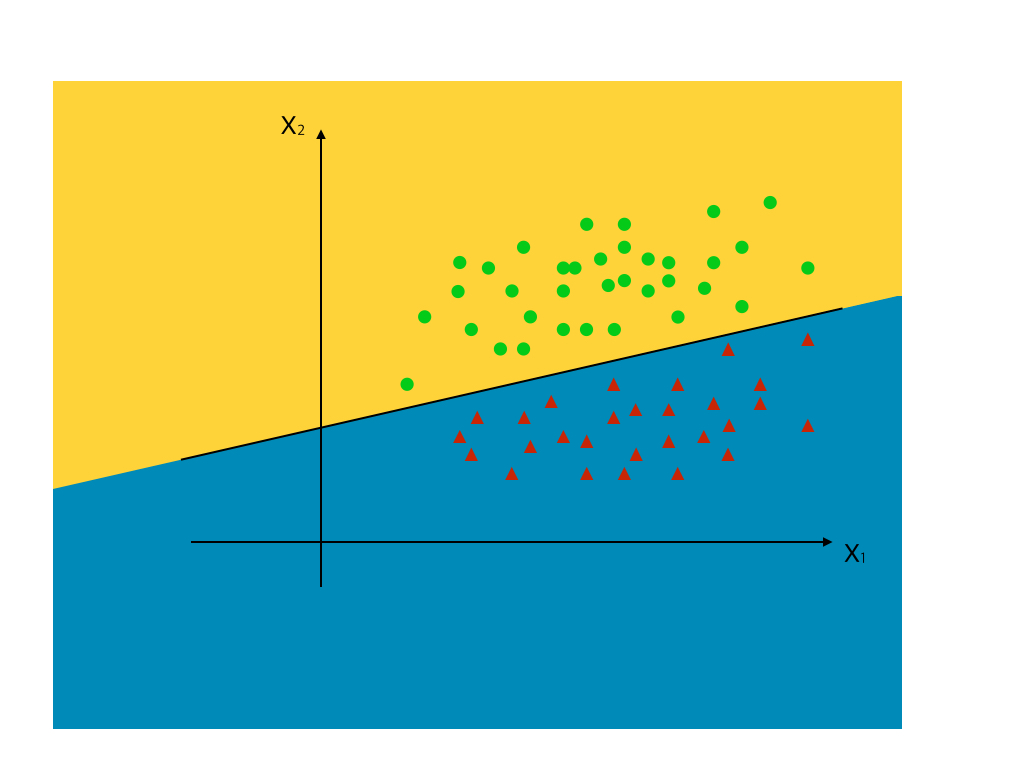
위처럼 선형으로 깔끔하게 분류가 가능한 문제는 활성함수가 계단함수인 단층 퍼셉트론으로도 충분히 해결할 수 있습니다. 하지만 아래와 같은 경우는 문제가 달라집니다.
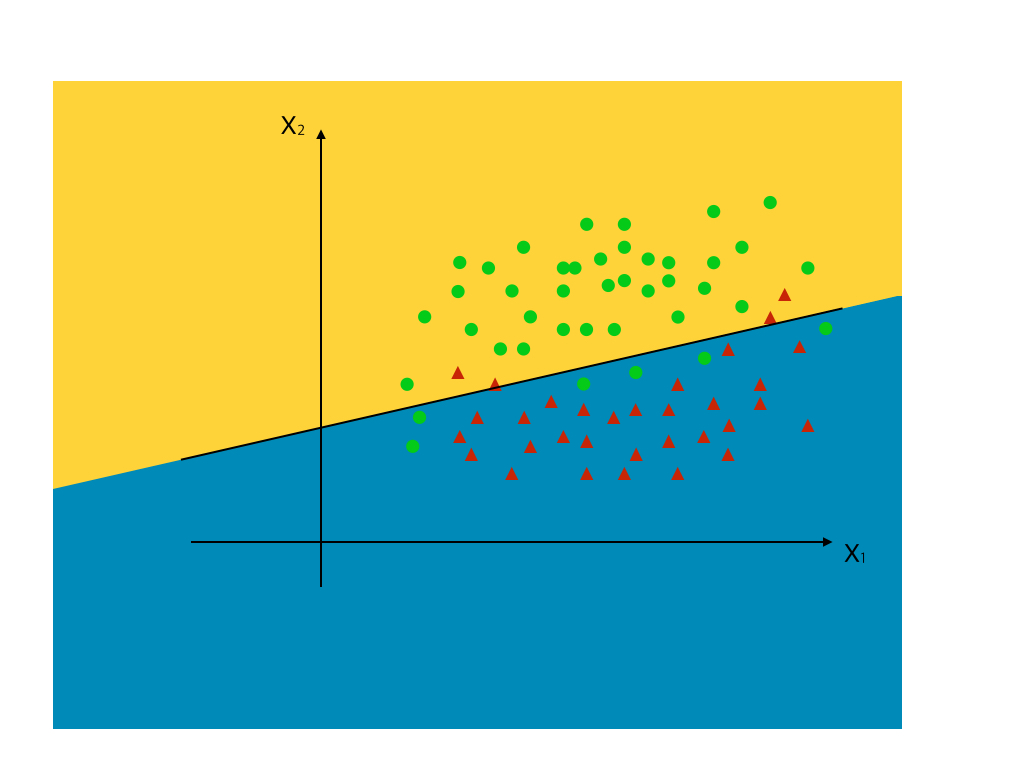
이러한 분류 문제는 선형으로는 불가능하며, 비선형적인 분류를 하여야 합니다. 이처럼 우리가 원하는 비선형의 분류를 하기 위하여 크게 두 가지가 필요합니다.
먼저 비선형의 활성함수가 필요한 이유부터 간단하게 생각해보겠습니다. 만약 활성함수가 비선형이 아니라면, 각 뉴런의 결과값은 선형결합의 선형결합이 됩니다. 따라서 아무리 multiple layer를 쌓는다고 하여도, 결과적으로 출력값은 입력값들의 선형결합이 됩니다. 즉, 층을 여러 개 쌓는 의미가 퇴색되는 것입니다.
다음으로 hidden layer와 뉴런의 갯수에 대한 정의가 왜 필요한지 생각해보겠습니다. 위에서 언급하였듯이 logistic regression은 generalized linear model입니다. 여기서 ‘linear model’에 주목해주세요. 즉, logistic regression도 결국은 선형 모델이라는 것입니다. 왜일까요? Logistic regression을 이항분류 문제(결과의 범주가 0 또는 1)에 적용하여, 결과값이 특정값 이상이면 1로 분류한다고 생각해보겠습니다. 이것은 결국 기존의 단일 퍼셉트론에서 활성함수로 sigmoid를 사용한 뒤, 다시 계단함수를 적용한 것과 같습니다. 비록 우리가 sigmoid라는 비선형의 활성함수를 사용했지만, 로지스틱 함수의 지수를 풀어내면 결국 선형 결합의 결과값에 대한 분류이므로 우리가 원하는 비선형의 분류를 할 수 없습니다. 따라서 위와같은 문제를 해결하기 위하여, 비선형의 활성함수를 쓰되, 다수의 뉴런을 갖는 hidden layer를 사용하는 것입니다. 이 때, hidden layer의 뉴런 갯수가 늘어날 수록 좀더 비선형으로 데이터에 적합한 분류가 가능해지지만 overfitting 문제가 발생하게 됩니다. 따라서 hidden layer의 뉴런 갯수를 과제마다 적절히 지정해주는 것이 중요합니다.
마지막으로 activation function의 종류 및 특징에 대해 정리해보겠습니다.
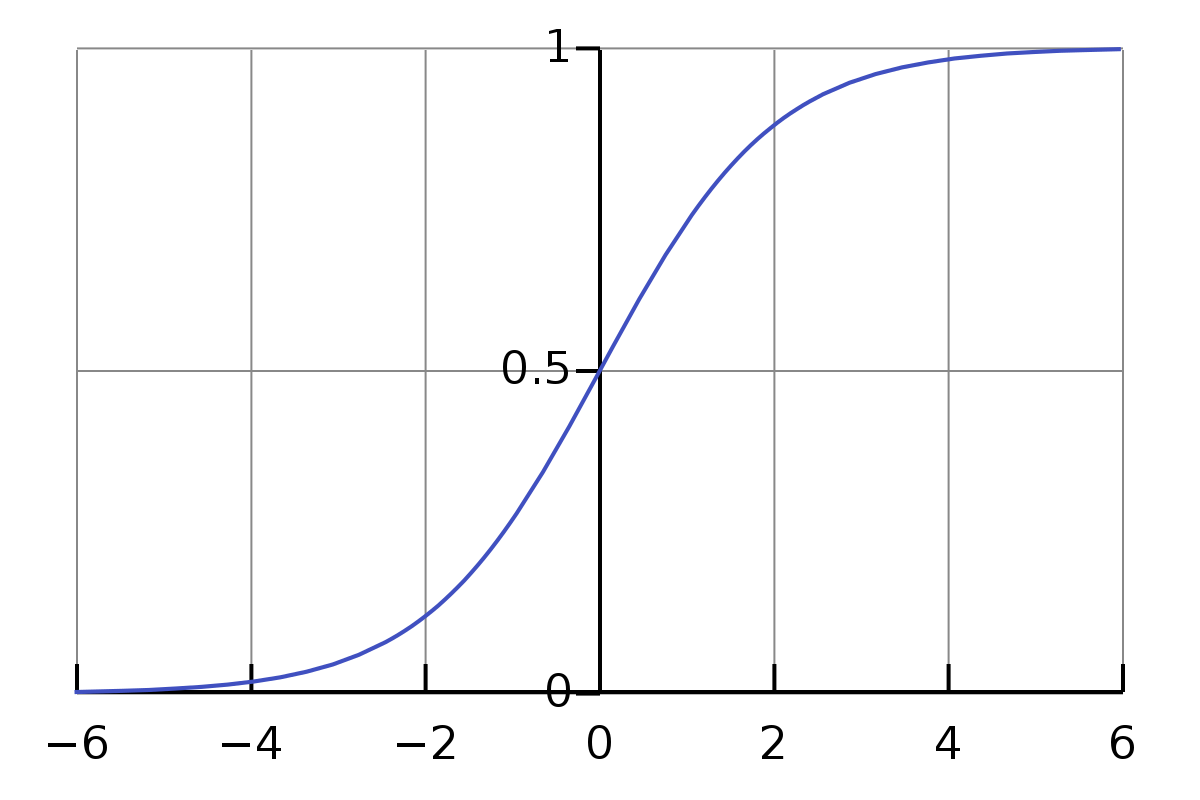
By Qef (talk) - Created from scratch with gnuplot, Public Domain, Link
시그모이드 함수는 완전히 값을 전달하지 않거나(0) 혹은 완전히 전달한다(1)는 특성 때문에 실제 인체의 뉴런과 유사하다고 생각되어 널리 사용되었으나, 현재는 점차 사용하지 않는 추세입니다. 그 이유는 아래와 같습니다.
Vanishing Gradient :
sigmoid 함수는 뉴런의 활성화 값이 0 또는 1에 매우 가깝다면(saturate), 해당 편미분 값이 0에 매우 가까워지는 특성이 있습니다. 인공신경망의 back propagation에서 가장 일반적으로 사용되는 gradient descent의 경우 chain rule을 이용하는데, 이 과정에서 0에 매우 작은 값이 계속 곱해진다면 그 값은 0으로 점점 더 수렴합니다. 즉, 학습의 결과가 back propagation 과정에서 전달되지 못하고 이에 따라 weight 값의 조정이 되지 않습니다. 이것은 학습의 과정뿐만 아니라, 초기 weight 값을 임의로 줄 때에도 문제가 됩니다. f=σ(wx+b)<math>
중심값이 0이 아니다 :
Sigmoid function의 결과값은 그 중점이 0이 아니며, 모두 양수입니다. 이 경우 모수를 추정하는 학습이 어렵다는 단점이 있습니다. 하지만 이것은 다른 방식으로 모델 내에서 극복이 가능하기 때문에 vanishing gradient 에 비해 큰 문제는 아닙니다.
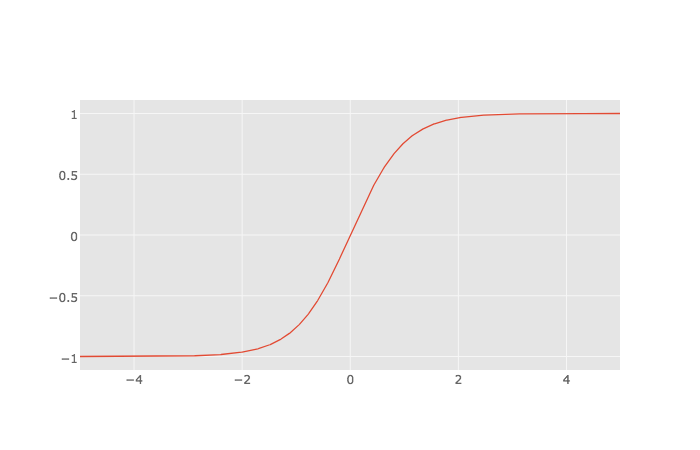
tanh(hyperbolic tangent) function은 sigmoid 처럼 비선형 함수이지만 결과값의 범위가 -1부터 1이기 때문에 sigmoid와 달리 중심값이 0입니다. 따라서 sigmoid보다 optimazation이 빠르다는 장점이 있고, 항상 선호됩니다. 하지만 여전히 vanishing gradient 문제가 발생하기 때문에 대안이 등장하게 됩니다.
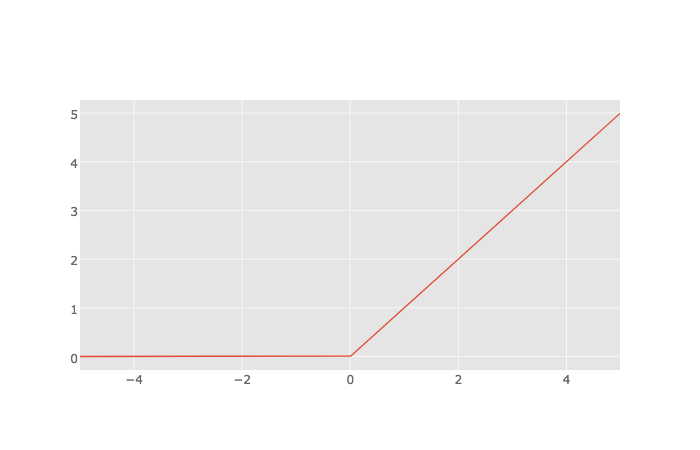
Relu는 위 그림처럼 선형그래프를 한 번 꺾은 형태입니다. 이 간단한 함수는 오랫동안 인공신경망의 발목을 잡던 vanishing gradient 문제를 해결했습니다. 하지만 여전히 장점과 단점이 존재합니다.
장점
단점
이번 포스팅을 통해 우리는 activation function이 무엇이고, 왜 필요한 것인지 알아보았습니다. 또한 어떠한 activation을 어떻게 사용해야하는지도 배웠습니다. 제가 위에 소개한 것 이외에도 다양한 activation function이 있으므로, 한 번쯤 찾아보며 공부해보시면 좋겠습니다.
 가입하기
가입하기