Photo by Alfons Morales on Unsplash
소개
안녕하세요. WATCHA에서 서버 개발을 하고 있는 Allan 이라고 합니다. 이번에 개발한 WATCHA 로그 분석 플랫폼에 대해 간략히 공유하고자 합니다.

이전 분석 방법
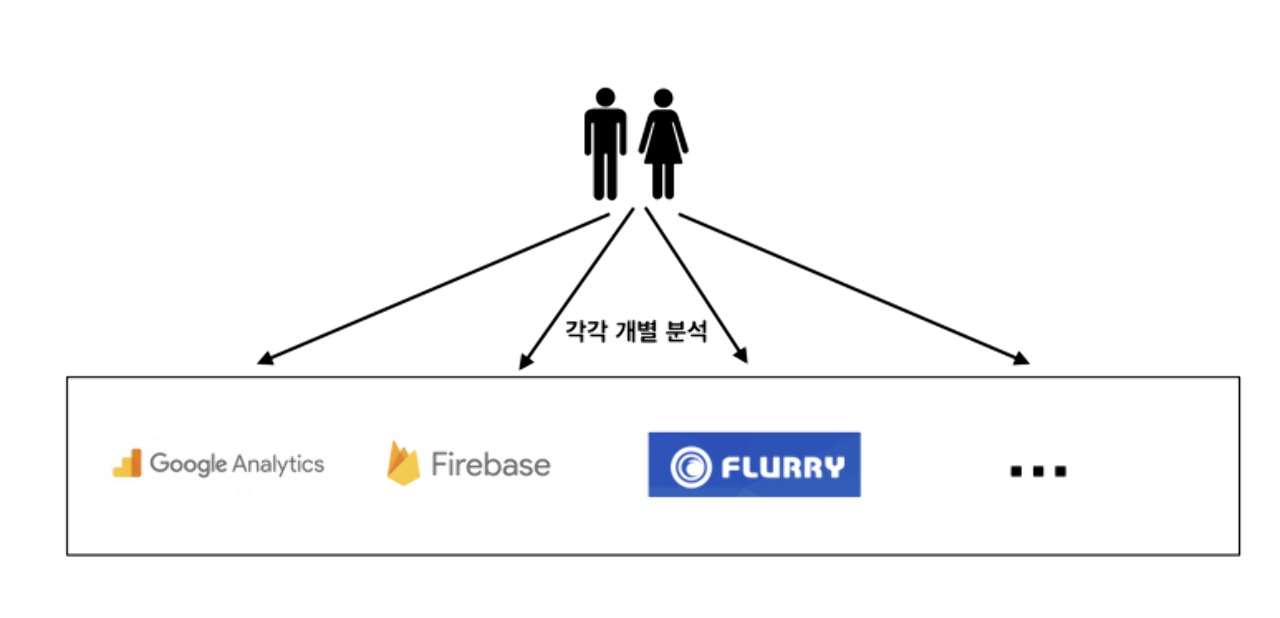
지금까지 WATCHA에서는 필요에 따라 로그 데이터를 접근성이 편리한 RDB에 저장하거나, 여러 외부 솔루션을 적용하여 다양한 패턴을 분석 하고 앞으로의 방향을 결정하거나 서비스 개선을 하고 있었습니다.
하지만 점점 서비스가 성장하고 사용자가 늘어남에 따라, 로그 데이터가 빠르게 증가하면서 기존에 구축된 방식을 이용해서는 분석이 어려워졌습니다.
그리고 여러 영역에 분산된 데이터의 통합 분석이 어려워져서 빠른 개선이 필요한 상황이었습니다.
그래서?
로그를 한곳에 통합하고, 데이터를 빠르게 분석 할 수 있고, 어떠한 환경에서도 유연하게 수집 및 가공이 가능한 시스템을 구축하기로 하였습니다.
1. 한곳에 통합
로그를 한곳에 저장, 빠르게 분석할수 있는 Google BigQuery를 이용하게 되었습니다. 선택했던 이유는 Google 솔루션인 FireBase, Google Analytics 등 클라이언트 영역에서 발생하는 로그들도 손쉽게 BigQuery에 통합이 가능하여, Web, App, Server 등 모든 영역에서 발생하는 로그를 한곳에 모을 수가 있기 때문입니다.
2. 빠르게 분석
한곳에 분석용 로그가 모여 있으면, 원하는 데이터를 쉽게 취합하여 분석할 스 있고, Google BigQuery를 이용하게 되면 대용량 데이터도 빠르게 분석하는 것이 가능합니다.
3. 유연하게 수집 및 가공
WATCHA 에서는 여러 서비스들이 AWS 내에 구성되어 있습니다. 서비스별로 Rails, Nodejs, Scala, Java, Python 등 다양한 플랫폼 및 언어로 구성되어 있고, 실행 환경도 다릅니다. 그래서 멀티클라우드, OS 및 특정 언어와 라이브러리에 종속되어 있지 않고, 실시간으로 로그를 유실 없이 수집하기 위해서 여러 기술을 사용하여 구현하였습니다.
사용 기술스택
전체 로그 시스템 구성 설명에 앞서, 사용한 기술에 대해서 간략하게 설명합니다.
멀티 클라우드(GCP, AWS, Elastic Cloud): 현재 WATCHA의 대부분의 서비스들은 AWS를 이용하여 서비스하고 있습니다. 그리고 로그 분석 시스템 중 인프라는 GCP를 이용하고 있으며 Elastic Search는 Hot-Warm 클러스터 구조로 Elastic Cloud에서 운영하고 있습니다. AWS <-> GCP 사이의 연결은 VPN으로 통신하며, VPN 연결은 해당 링크 를 참고 하시면 됩니다.
Kubernetes: 도커 컨테이너 오케스트레이션 플랫폼이며, WATCHA에서는 Helm을 이용하여 배포, 운영중에 있습니다. 로그 모니터링 시스템은 Consul, Prometheus, Grafana 와 데이터 가공툴은 Airflow, Embulk 를 운영하고 있습니다.
Fluent-Bit: Fluentd 의 경량버전입니다. C로 구현되어 있고, 라이브러리에 의존성이 없습니다. Fluentd보다는 가볍고 빨라서 대용량 로그 수집에 최적화 되어있습니다. 단점으로는 Zero Dependencies를 지향하고 있어 기본적으로 제공하는 기능이 적습니다.
PubSub: GCP에서 SAAS형태로 제공하는 Queue 서비스입니다. 대용량에 최적화 되어 있으며, 비슷한 기술로는 Kafka 와 비교 되고 있습니다.
Consul, Prometheus, Grafana: Consul은 Service Discovery 서비스이고, Prometheus은 Metric 수집, Grafana는 수집한 Metric을 Visualization하는 서비스입니다. WATHCA에서는 해당 서비스들을 로그 모니터링 시스템에 사용하고 있습니다.
BigQuery: 모든 로그저장 및 분석용으로 사용합니다. Standard SQL 형태로 검색 가능하며, FireBase, Google Analytics 데이터도 BigQuery에 통합 가능합니다.
AirFlow: 데이터 가공을 위한 플로우를 관리하는 서비스입니다. WATCHA에서는 BigQuery에 있는 데이터를 여러 단계로 나눠서 원하는 데이터 생성(ETL) 시 이용하고 있습니다.
Embulk: 여러 데이터소스로부터 다른 곳으로 Migration 해주는 서비스 입니다. 현재 WATCHA에서는 RDS데이터를 BigQuery로 Migration 하며, 좀더 분석이 편리하도록 하고 있습니다.
Flexible App Engine: GCP에서 Docker로 배포하고 자동으로 Autoscaling 해주는 SAAS 형태로 제공하는 솔루션입니다. 여기에서는 Pubsub으로 받은 Data를 분석하여 처리하는 작업에 이용합니다.
DataStudio: Google에서 제공하는 Visualization 솔루션입니다. BigQuery와 통합하여 가공한 데이터를 그래프 형태로 사내에 공유하고 있습니다.
CloudBuild: GCP에서 제공하는 CI/CD 툴입니다. CI/CD Pipeline을 구축하여 코드 Commit 시 TestCase에 통과되면 자동으로 배포되도록 이용하고 있습니다.
Terraform: Code로 인프라를 관리해주는 툴로서 GCP 인프라 설정은 Terraform을 이용하고 있습니다.
Golang: 동시성 처리 부분에 우수한 성능과 편리성을 제공하는 언어입니다. WATCHA에서는 Fluent-Bit 플러그인 개발이나 실시간으로 받은 데이터를 가공 후 처리할 때 등 여러 로직에서 이용하고 있습니다.
Protocol Buffers: 여러 언어를 지원하는 직렬화 프로토콜입니다. WATCHA에서는 로그구조를 Protobuf로 정의 후, 여러팀에 문서화 필요없이 쉽게 공유하며, 사용언어에도 구애받지 않고 로그 수집에 이용하고 있습니다.
전체 로그 시스템 구성
로그 시스템은 수집파트, 처리파트, 모니터링파트 총 3부분으로 나누어져 있습니다. 아래는 전체적인 로그 시스템 구성도 입니다.

전체 로그 시스템 구성도
수집부분
로그 파일에서 데이터를 수집하여서 전송하거나, 서비스내에서 직접로그를 전송하는 경우, 여러환경(사용언어, 라이브러리, OS ..등)을 고려해야 하고, 로그를 추가할 때마다 SPEC에 대한 커뮤니케이션 비용이 발생하는 애로사항이 많습니다. 그래서 로그구조를 쉽게 공유하고, 여러언어로 라이브러리로 제공 할 수 있는 Protobuf를 표준 프로토콜로 이용하고 있습니다.

수집 부분
수집 부분에서는 총 3가지 방식으로 로그를 수집하고 있습니다.
FireBase: FireBase를 사용해 Client에서 발생하는 로그를 수집합니다. 관리툴에서 설정만 조절하면 쉽게 BigQuery로 Migration 됩니다.
Fluent-Bit: 여러 서비스의 로그 파일에서 로그를 수집합니다. Fluent-Bit 기능이 적은 관계로, PubSub으로 로그전송과 모니터링을 위해 Consul에 등록하는 플러그인을 Golang 개발 후 C Shared Library형태로 컴파일해 이용하고 있습니다. 전송 포맷은 Protobuf를 이용하고 있으며, 다른 서비스에 추가 시에 쉽게 배포가 가능하도록 CLI툴을 개발하여 배포하고 있습니다.
Direct 전송: 결제 이력과 같은 주요 이벤트는 서비스에서 직접 전송하고 있습니다. 전송 포맷은 Protobuf를 이용하고 여러 언어(Ruby, Scala, Javascript, Go .. 등)로 라이브러리 형태로 제공하여 편리하게 전송가능합니다.
처리부분
PubSub으로 받은 데이터와 AWS내에 있는 RDS 데이터를 BigQuery에 저장하거나, BigQuery에 저장된 데이터를 배치처리로 가공, 분석 및 Visualization 하는 부분을 담당합니다.
그리고 실시간 분석 및 모니터링을 위해서 Elastic Cloud에서 Elastic Search 및 Kibana를 이용하고 있습니다.

처리 부분
실시간 가공 및 처리: Pubsub에서 로그를(Protobuf 형태) 전송받아 가공 후 저장을 하고 있습니다. 데이터 가공 및 처리 부분은 새로운 형태의 로그가 추가되거나 변경이 일어나더라도 자동으로 알아서 BigQuery 테이블에 저장합니다. 그리고 중복된 로그는 조건에 따라 자동으로 필터를 할 수 있고, Elastic Search 와 같은 실시간 데이터가 필요한 곳에 원하는 형태로 전달해줄 수 있는 다양한 용도로 이용하기 위해 개발했습니다.
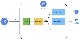
실시간 가공 및 처리 과정
동시성을 처리하는 데 있어 개발 편리성과 성능에 장점이 있는 Golang으로 개발했습니다. 또한 성능적으로도 튜닝하여 적은 머신으로 많은 데이터를 빠르게 처리하고 있습니다.
간략하게 프로세스를 정리해보면 Pubsub으로부터 Protobuf 포맷의 데이터를 Restful API로 받아 스키마 및 데이터를 분석하여, 비동기로 동작하는 Worker들에게 전달하여 해당 목적에 맞게 수행하도록 되어 있습니다.
로직 변경 없이도 새로운 로그 포맷에 대응할 수 있도록 되어 있고, 상황상 발생할 수 있는 중복데이터는 해쉬를 이용한 중복 체크 및 로직을 통해 중복 저장되지 않도록 구현되어 있습니다.
해당 프로세스는 Flexible App Engine에서 동작하고 있고, CloudBuild로 CI/CD 파이프라인을 구현하여 코드 변경 시 자동으로 트리거되어 TestCase 통과후 자동으로 배포 되고 있습니다.
배포 방식은 카나리(Canary)로 하고 있어, 일부 트래픽을 새로 배포된 프로세스로 옮기고, 이상 징후가 없을 시 전체 트래픽을 옮기는 방식으로 운영하고 있습니다.
Embulk를 이용한 BigQuery 저장: 서비스 데이터는 AWS내에서 RDS로 저장되어 서비스에 이용되고 있습니다. 로그만으로 데이터를 분석하기에는 한계가 있고, 서비스 데이터도 BigQuery내에서 로그와 함께 분석하면 좀더 정확한 데이터를 얻을수 있어 주기적으로 Embulk를 통해 RDS 데이터를 BigQuery에 동기화 하고 있습니다. Embulk 프로세스는 Packer를 이용해 빌드후 주기적으로 K8S Pod 형태로 돌고 있습니다.
Elastic Cloud 이용한 실시간 분석: BigQuery와 같은 빅데이터 분석용으로 만들어진 솔루션은 실시간 분석, 가벼운 검색 및 특정 상황에 대한 모니터링에 이용하기에 비용, 성능에 있어서 적합하지 않습니다. 그래서 Elastic Cloud에서 Elastic Search 와 Kibana를 SAAS형태로 이용하고 있습니다.

Elastic Cloud (HOT-WARM) 구조
Elastic Cloud에서 Elastic Search와 Kibana를 이용하게 되면 Elastic사에서 직접 관리 해주고 Downtime 없이 ElasticSearch 업데이트가 가능하며, X-PACK 및 Custom 플러그인도 손쉽게 사용가능하게 되어 있습니다.
현재 WATCHA에서는 Hot-Warm 클러스터 구조로 Elastic Search를 구성하여서, 최신 데이터는 Hot 노드에 저장하고, 일정 기간이 지난 데이터는 자동으로 Warm 노드로 이동시키고 있습니다.
X-PACK을 이용하여 Kibana에 Single Sign On을 적용해 쉽게 로그인이 가능하고, Security 설정 및 모니터링에 적극 활용하고 있습니다.
가공 및 Visualization: BigQuery에 1차 가공되어 저장된 데이터에서 좀더 원하는 정보를 얻거나, 특정 지표를 보여주기 위해서는 더 세부적인 데이터 가공이 필요합니다. 그래서 AirFlow를 이용해서 여러 단계로 걸쳐 데이터를 가공하여서 BigQuery 또는 Storage에 저장을 하고 있습니다. 이렇게 가공된 데이터는 DataStudio로 그래프 형태로 만들어져 사내에 공유하고 있습니다.
모니터링 부분
로그 수집 부분은 로그 플랫폼에서 아주 중요한 부분을 차지 합니다.
모니터링 부분은 이런 로그 수집에 대한 모니터링 및 대응을 하기 위해 만들어 졌습니다.
물론 만들어진 배경은 이전에 예상치 못한 문제로 로그수집을 이뤄지지 않고 로그가 유실되는 상황이 있었습니다.(유실된 상황을 인지하는데도 오랜 시간이 걸렸습니다.)
서비스 중인 서버들뿐만 아니라 새로 개발되는 서비스 서버들도 유동적으로 변화하는 환경에서 대응할수 있도록 개발했고, Kubernetes + Helm을 이용하여 손쉽게 배포 및 관리를 하고 있습니다.
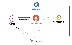
모니터링 부분
Consul: Fluent-Bit가 Consul에 등록을 하게 되면, 서비스별로 로그 수집 Agent가 Live한지 확인이 가능합니다. 방법으로는 주기적으로 HealthCheck 메시지를 보내어 로그 수집 Agent가 Live한지 체크합니다.
Prometheus: Consul을 이용하여 서비스별로 Live한 Agent 리스트를 찾아, 직접 Agent에 접근하여 Metric을 수집합니다. CPU/메모리 사용량, 수집된 로그의 IN/OUT 수치 등을 수집합니다.
Grafana: Prometheus에서 수집한 Metric을 Visualization해서 보여줍니다. 또한 모니터링 알림을 설정하여, 이상이 있을 시 Slack으로 알림을 전송합니다.
설명해보면, Fluent-Bit는 시작 시 Consul에 서비스를 등록하게 되고, 등록된 Fluent-Bit Agent 기반으로 모니터링하게 됩니다. 만약 Fluent-Bit 프로세스가 문제가 발생해 죽게 되면, 서비스중인 서버 리스트와 Consul에 등록된 서비스중인 리스트를 비교하여 알림으로 알려주게 되어 있습니다.
또한 Fluent-Bit가 떠있더라도 문제가 발생해 로그가 전송되지 않은 상황에 있더라도, Input/Ouput 처리량을 분석하여 알림으로 알려주도록 되어 있습니다.
모니터링 부분은 전반적으로 로그 유실을 최소화하기 위한 목적으로 만들어져 있습니다.
배포/인프라 관리
배포 및 인프라 관리는 모든 개발 영역에서 필수적인 부분입니다.
전반적으로 잘 만들어진 Tool을 사용하고, 코드로 관리하도록 해서 Manual하게 사람이 배포 및 관리하는 작업을 최소화하는 방향으로 진행하였습니다.
간략하게 정리해보면
AWS 및 GCP 인프라 구성: Terraform 으로 관리되어 있어, 코드로 인프라를 관리하게 되어 변경이력을 알기 쉽고, 편리하게 이용하고 있습니다.
Log Agent: 배포를 위한 CLI TOOL을 직접 개발하여 운영을 하고 있습니다.
Embulk: Packer를 이용하여 빌드후 Private Docker Hub에 저장하고 있습니다.
Data Pipeline(Go): CloudBuild를 이용하여 Github에 Commit이 되게 되면 자동으로 트리거 되어 TestCase 통과 후 카나리(Canary) 배포를 하고 있습니다.
K8S Application: HELM 패키지 매니저를 통하여 배포를 하고 있습니다.
결론
지금까지 멀티클라우드 환경에서 로그 수집, 로그 가공, 로그 모니터링, 배포/관리에 이용했던 기술에 대해 공유해 보았습니다.
한가지의 클라우드 서비스만을 이용하기보다는, 다른 클라우드에 있더라도 장점이 있는 솔루션을 이용할 수 있다면, 좀더 유연하게 서비스를 운영할 수 있습니다.
대용량 데이터 분석에 큰 메리트가 있는 BigQuery를 이용하여 클라이언트, 서버 등의 데이터를 통합하여 다양한 분석이 가능해 졌고, Standard Query 형태로 분석이 가능해 접근성도 많이 좋아졌습니다.
그리고 Elastic Cloud를 이용하면 Hot-Warm 구조 ElasticSearch 클러스터를 손쉽게 운영하는 것이 가능하며 SSO, Security 등 X-PACK 및 Custom 플러그인 사용이 가능합니다. 또 Elastic사에서 직접 개발 서포트 및 Downtime 없는 빠른 업데이트를 할 수 있어 큰 메리트가 있습니다.
지금까지 왓챠와 왓챠플레이의 이용자가 늘어나고 서비스가 커져 감에 따라 분산돼 있던 로그 분석 시스템을 멀티클라우드를 이용해 통합한 과정에 대해 이야기해 드렸는데요, 여전히 서비스 성능을 개선하기 위해 앞으로 더 진행해야 할 과제들이 많이 남아있습니다. 왓챠에서는 이처럼 서비스도 발전시키고 자신도 성장하는 데 관심이 많은 능력 있는 개발자를 모집하고 있습니다. 관심있는 분은 채용공고를 참고해주세요.
긴글 읽어 주셔서 감사합니다.
 가입하기
가입하기