우리 팀은 과학적인 사용자 데이터 분석 및 실험을 매우 중요하게 여긴다. 약 3년 전 데이터 분석에 대한 고민을 시작하였을 때, 우리는 쉽고 빠르고 강력하면서 동시에 경제적인 분석 플랫폼을 찾기가 생각보다 훨씬 힘든 일임을 깨달았다. 데이터 분석이나 관련 시스템 구축에 특화된 팀원도 없었다. 상용 솔루션을 사용하기엔 알라미의 활성 유저수로는 년간 수천만 원 이상이 들것으로 예상되어 부담이 컸다.
Firebase + BigQuery를 우리의 주 분석 플랫폼으로 선택한 것은 당시 우리로서는 당연한 선택이었다. Firebase는 구글에 인수된 후 종합적인 모바일/웹 백엔드로서 재탄생했다. 무엇보다도 무료로 analytic 기능을 제공한다는 점이 매력적이었다. 더욱이 Firebase는 이벤트 raw 데이터를 BigQuery로 분석할 수 있는 기능(유료이다)을 지원하였다. 이는 부실한 Firebase 자체 분석 기능을 잘 보완해주었다. 2017년 중반까지 한 동안 BigQuery를 우리의 주요 분석 툴로 활용했다.
왜 BigQuery를 버리고 다른 대안을 찾기로 하였는가?
BigQuery는 데이터 쿼리 용도로는 충분히 강력하다. 그러나 다음 이유로 우리는 BigQuery가 우리의 필요를 충족시켜주지 못한다고 느꼈다.
1. 쿼리 작성이 쉽지 않음

쿼리 작성이 짜증나는 일이라면 누가 분석을 하려할까 (이미지 출처: Freepik)
이는 사용자 속성, 이벤트 및 파라미트정보가 nested 되어있는 DB 구조에 기인한다. 우리 팀은 전담 데이터 분석가가 없다. 팀원 모두가 각자 시간을 써서 나름대로 분석을 진행한다. 때문에 쿼리 작성과 결과 해석이 가능한 한 쉬워야 한다. 데이터 분석가가 주 포지션인 팀원의 경우 기본적인 전문성은 차치하고서라도, 어느 정도 learning curve를 감당할 수 있다. 하지만 다른 포지션의 팀원들은 분석과정이 조금만 어려워져도 접근이 매우 힘들게 된다. BigQuery 쿼리 짜는 난도가 높다는 점은 우리 팀이 자유롭게 분석을 시도해보는데 큰 걸림돌이었다.
2. 부족한 실시간성

처리 속도 측면에서 BigQuery가 크게 모자란 도구는 아니다. 하지만 우리의 주요 use case는 복잡하고 무거운 분석을 백그라운드에서 돌리는 것이 아니라, 실시간으로 간단한 분석들을 하는 OLAP(Online analytical processing)이었다. BigQuery는 실시간성이 충분히 높지 못했다.
3. 비용
BigQuery는 쿼리 시 참조하는 데이터량에 비례하여 과금된다. 우리 서비스의 경우 데이터량이 작지 않기 때문에, 쿼리를 걱정 없이 자유롭게 하려면 비용이 적지 않게 들것으로 예상되었다. 이 측면에서 우리는 가능하면 사용량에 따른 과금의 부담 없이 자체적인 서버에서 분석을 진행할 수 있었으면 했다.
서비스가 성숙해 나가면서, 상기 단점들은 우리의 빠른 성장에 치명적인 병목이 되었다. 팀원 모두가 매끄러운 분석 파이프라인 구축의 필요성을 통감하였다. 이때부터 우리 서비스 특징 및 팀의 분석 니즈에 맞는 분석 파이프라인 구축에 나섰다.
새로운 데이터 분석 파이프라인
여러 alternative들이 물망에 올랐다. 때마침 Microsoft에서 Sponsorship을 지원받아 Azure를 마음껏 사용할 수 있는 기회가 생겼다. 상용 서비스 사용보다는 자체적인 서버 구축에 더욱 힘이 실렸다. 최종적으로 Firebase로 데이터 수집 후, 이를 ClickHouse로 migrate 하여 Zeppelin으로 분석하는 파이프라인을 구축하였다.
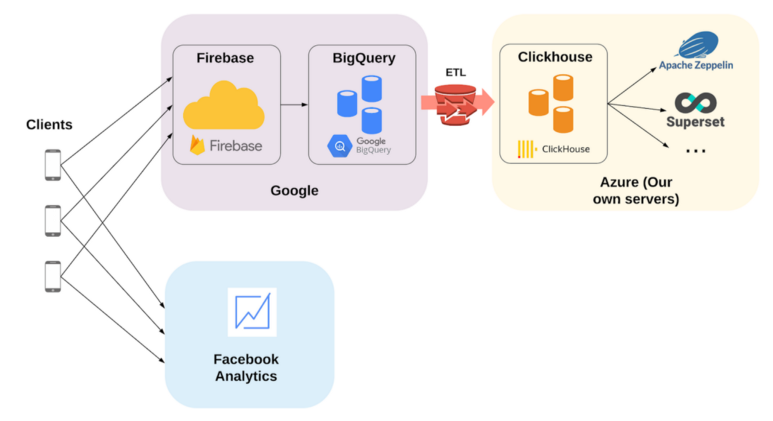
새로운 Clickhouse 기반 데이터 분석 파이프라인
네 가지 Key Component들을 짚어보겠다.
1. Firebase를 이용한 데이터 수집
우리는 데이터 수집 도구를 직접 만들고 운용하는 대신 Firebase를 이용하기로 하였다. BigQuery를 통해 raw 데이터를 export 하여 우리 DB로 옮길 수 있었기 때문이다. Firebase만큼이나 안정적으로 유저의 데이터를 수집하는 시스템을 별도로 구축하는데 시간과 인력을 투자하는 것은, 제품 자체에 집중해도 시간이 모자란 우리 팀에는 맞지 않다고 생각했다. 물론 BigQuery에서 데이터를 옮기는 데는 별도의 비용이 들지만 우리가 감당할 수 있는 정도였다.
2. ETL: Data flattening
우리 팀은 Firebase(BigQuery)에서 ClickHouse로 옮겨오는 일종의 ETL(Extract-Transform-Load) 프로그램을 만들어 사용한다. 이 과정은 단순히 데이터를 옮기는 것이 아니라 우리가 원하는 방식으로 가공하여 저장한다는 점에서 매우 중요하다.
BigQuery 데이터의 경우 앞서 언급하였다시피 각종 파라미터 및 유저 데이터가 하나의 이벤트 레코드 안에서도 nested 되어 저장되어있다. 현재는 BigQuery의 Firebase 데이터 저장 schema가 조금이나마 개선되었지만 (2018년 6월 이후부터), 이 파이프라인을 처음 구축할 때는 schema가 더욱 복잡하였다.
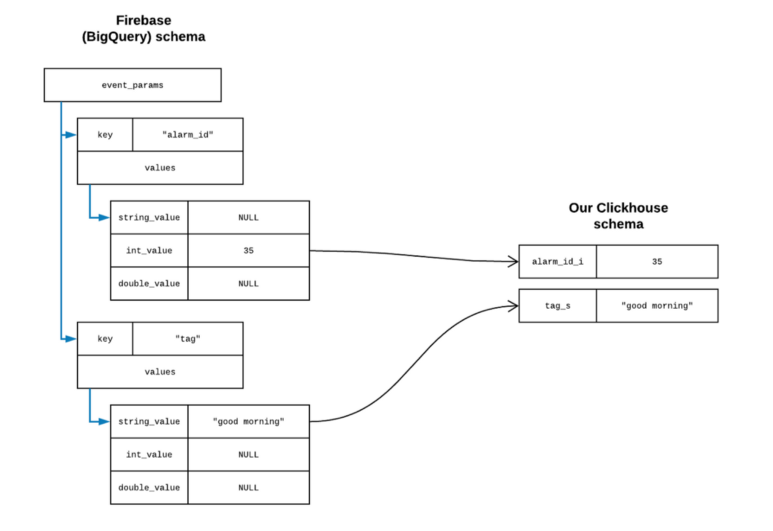
Example of flattening
이 복잡성을 해소하기 위해서, ETL 과정에서 모든 nested 데이터를 펼친다. 2~3겹으로 이루어진 데이터는 무조건 1겹이 된다. 이벤트 파라미터 데이터를 예로 들어 보자. alarm_id라는 키와 35라는 정수 값을 가진 중첩 구조의 파라미터는 alarm_id_i라는 하나의 필드로 변환된다. alarm_id_i라는 이름에서 앞의 alarm_id는 파라미터의 키, _i는 파라미터의 값의 타입을 의미한다. 이제 파라미터에 관련된 쿼리를 할 때, BigQuery의 UNNEST, Spark의 explode 같은 함수를 쓸 필요 없다. 파라미터 이름과 타입만 알면 다른 여느 필드와 같은 레벨에서 쿼리 할 수 있다. 대신 수백 개의 필드가 새로 추가되게 된다. 기존 row-oriented 데이터베이스의 경우에는 이는 문제가 되었겠지만, column-oriented 데이터페이스인 ClickHouse의 경우 아무 문제없다.
3. Clickhouse
ClickHouse는 OLAP을 위해 Yandex에서 만든 오픈소스 칼럼 기반 DB이다. 그렇게 잘 알려져 있지는 않다. 다양한 칼럼 기반 DB를 시도해보던 중 매우 빠른 쿼리 처리 속도가 눈에 띄어 사용하기로 마음먹었다.
장점
손쉬운 셋업 (cluster, replication 포함): 매우 빠른 시간 안에 우리 데이터를 넣고 돌려볼 수 있었음
매우 빠른 처리 속도: 일상적인 aggregation 작업들은 거의 실시간으로 처리해냄
단점
불안정성: 역사가 짧고 변화가 계속되는 프로젝트임. 아직 널리 쓰이지 않아서 검증이 되지 않음.
서드파티 지원 미비: DB 관리 툴이나 분석 툴에서 지원이 미비함. 예를 들어 Tableau에서 ClickHouse를 데이터 소스로 쓰기 쉽지 않음.
다음은 ClickHouse에서 8월 22일부터 일일 신규 유저 수를 구하는 예시이다. ClickHouse의 경우 0.071 초만에 구해냈지만, BigQuery의 경우 같은 쿼리를 돌리면 3초가 넘게 걸린다.
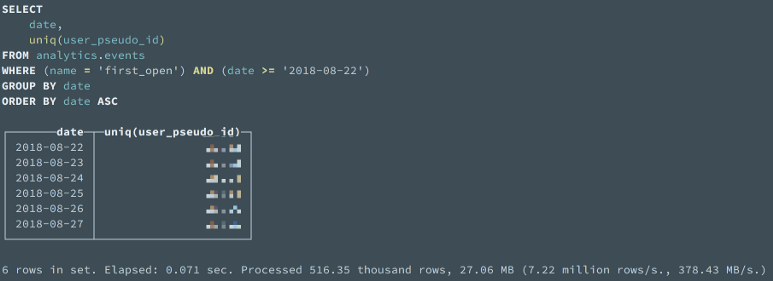
일일 신규 유저 수를 구하는 Clickhouse query
What about Spark? or XXX?
BigQuery의 대체제를 찾는 동안 ClickHouse 외에도 여러 가지 솔루션들이 고려대상에 올라왔다. 대표적으로는 Druid, Spark 등이 있겠다. 어떻게 해서 ClickHouse가 모든 후보군들을 제쳤는지는 추후 별도의 글에서 다뤄보겠다. 간략하게 이야기하면, 최소한의 세팅 및 튜닝으로 우리가 주로 작업하는 쿼리들을 매우 빠르게 돌려주었다는 점이 가장 마음에 들었다. 앞서 언급되었다시피, 우리 팀에는 데이터 분석가나 데이터 분석 인프라를 구축하는데 특화된 팀원이 없다. 그래서 어떤 시스템을 시도해보는데 결과가 어떻게 나올지도 모르는 세팅 및 튜닝에 많은 시간을 들일 수 없었다. 예를 들어 Spark를 사용한다고 했을 시, 우리 데이터 특성과 가용 컴퓨팅 리소스 등에 맞게 튜닝을 잘 한다면, 어쩌면 ClickHouse보다 더 좋은 성능을 보였을 수도 있다. (실제로 그럴지는 모르겠다. 단순한 예시로 봐주시라.) 그러나 ClickHouse가 이미 우리의 요구사항을 어느 정도 만족시킨다면, 단지 조금 더 좋을 수 있다는 가능성 때문에 Spark 튜닝에 많은 시간을 쏟을 수는 없지 않은가.
4. Zeppelin
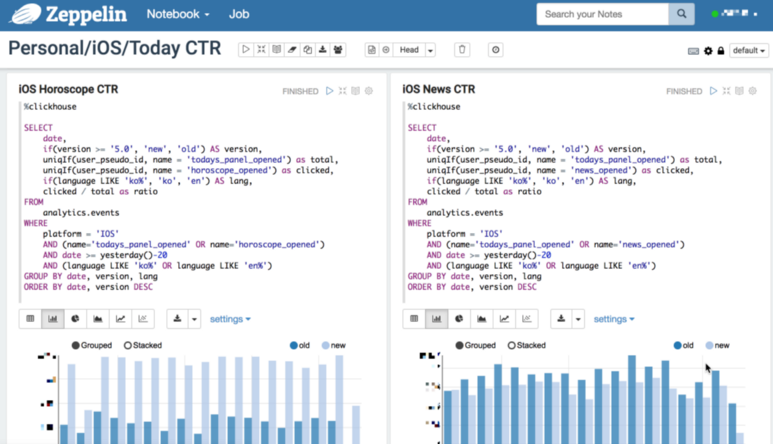
Zeppelin은 웹상에서 노트북 형식으로 인터랙티브 하게 쿼리를 실행하고 결과를 visualize 해주는 오픈소스 툴이다. Spark를 잘 지원하는 것으로 알려졌다. Spark뿐만 아니라 여러 가지 언어/실행환경을 Interpreter 플러그인 시스템으로 지원한다. 한 노트북 내에서도 실행 단위인 Cell마다 인터프리터를 바꿔가며 사용할 수 있다. Python, Spark, MySQL 그리고 Bash shell 등 다양한 코드를 즉석에서 실행하여 볼 수 있다. ClickHouse 역시 interpreter로 사용할 수 있다.
장점
간편한 사용법: 노트북 인터페이스로 초보자 라도 간편하게 쿼리를 실행하고 결과를 기록할 수 있음
웹 기반으로 온라인 협업과 결과 공유가 용이
다양한 Interpreter 지원
무료
단점
비교적 약한 visualization 도구
상용 서비스가 아닌 만큼 직접 서버에 설치, 운용해야 하며 특별한 사용자 지원은 없음
Setup
우리는 하루에 백만 명 이상의 유저로부터 1억 개 이상의 이벤트를 수집한다. 현재 300일어치가 넘는, 단순 계산으로는 수백억 개의 이벤트가 우리의 ClickHouse DB 서버에 저장되어있다. 이를 3개의 노드로 이루어진 클러스터를 만들어 분산하여 저장 및 쿼리를 실행한다. 각 노드는 Ubuntu 16.04가 설치된 Azure VM이며, 64GB~128GB 램에 16~32 코어 CPU의 성능을 가지고 있다.
Zeppelin사이트가 모든 팀원에게 열려있어서 누구나 쉽게 접속하여 실시간으로 쿼리를 돌려볼 수 있다. 모두가 항상 intensive 하게 매 순간 쿼리를 돌리는 것은 아니지만, 어느 정도 동시에 쿼리를 날리는 것에는 큰 무리가 없는 정도로 셋업이 되어있다. 만약 ClickHouse 서버가 힘에 부쳐한다 싶으면 노드를 추가하거나 성능을 업그레이드하는 방식으로 해결을 해야 할 것이다.
비용
공정하게 이야기하면, 위의 cluster setup을 유지하기 위해서는 어느 정도 비용이 든다. 우리 팀의 경우 Azure Sponsorship의 도움을 받아 실질적인 비용은 크게 줄어들었다. 만약 자체적인 ClickHouse cluster를 꾸미고 싶다면 BigQuery나 Redshift 같은 hosted data warehouse 혹은 다른 상용 분석 플랫폼과의 비용 차이를 잘 계산해 보아야 할 것이다.
마치며
ClickHouse 기반 분석 파이프라인이 가동되고 나서, 우리의 분석 속도는 기존의 10배, 아니 100배 이상 빨라졌다. 이는 단순한 쿼리 처리속도뿐 아니라, 쿼리를 짜는데 걸리는 시간 단축과 쿼리를 동시에 더 많은 사람이 짤 수 있다는 점에서 더더욱 단축된 결과다. A/B 테스팅, cohort 분석 등도 무리 없이 하게 되었다.
DDA(Daily Data Analysis)라는, 팀원 모두가 데이터를 통해 새로운 인사이트를 발견하는 세션을 가지게 되었다. DDA에서 얻은 결과들은 실제로 우리의 Decision making에 지대한 영향을 끼치기도 한다. 새로운 파이프라인은 우리 팀의 데이터 기반 성장에 필수적인 도구로 자리 잡았다.
중/소규모의 서비스에서 괜찮은 퍼포먼스를 보이고 빠르게 up and running 할 수 있는 OLAP용 DB가 필요하다면, ClickHouse를 시도해보는 것을 추천한다. ClickHouse는 Yandex, Cloudflare 등 큰 규모의 회사에서 사용됨에도 불구하고, 다른 널리 쓰이는 솔루션에 비하면 enterprise 환경에서의 검증은 아직 미흡하다. 어느 쪽이건 데이터 손상에 대비한 조심성 있는 접근이 필요하다.
마지막으로 이렇게 굉장한 오픈소스 소프트웨어들을 만든 ClickHouse 팀과 Zeppelin 팀 그리고 그 외 기여자들에게 감사를 전하고 싶다.
We are Hiring!
데이터 기반 결정을 내리고, 팀에 필요한 기술적 도전들을 중요시 하는 딜라이트룸에 관심이 있다면 직군과 상관없이 아래 링크를 클릭!
>>http://bit.ly/2PAekgT<<
참고자료/읽을거리
ClickHouse 공식 사이트
Zeppelin 공식 사이트
https://github.com/yandex/clickhouse-jdbc
ClickHouse: New Open Source Columnar Database
HTTP Analytics for 6M requests per second using ClickHouse (Cloudflare)
Comparison of the Open Source OLAP Systems for Big Data: ClickHouse, Druid and Pinot
ClickHouse in Real Life. Case Studies and Best Practices, by Alexander Zaitsev
Acknowledgements
Images designed by Graphiqastock / macrovector / Freepik
 가입하기
가입하기



