들어가며
얼마 전에 오픈한 베이글코드의 사내 데이터 디스커버리 툴, 아문센(Amundsen)에 대해 이야기해보려 합니다.
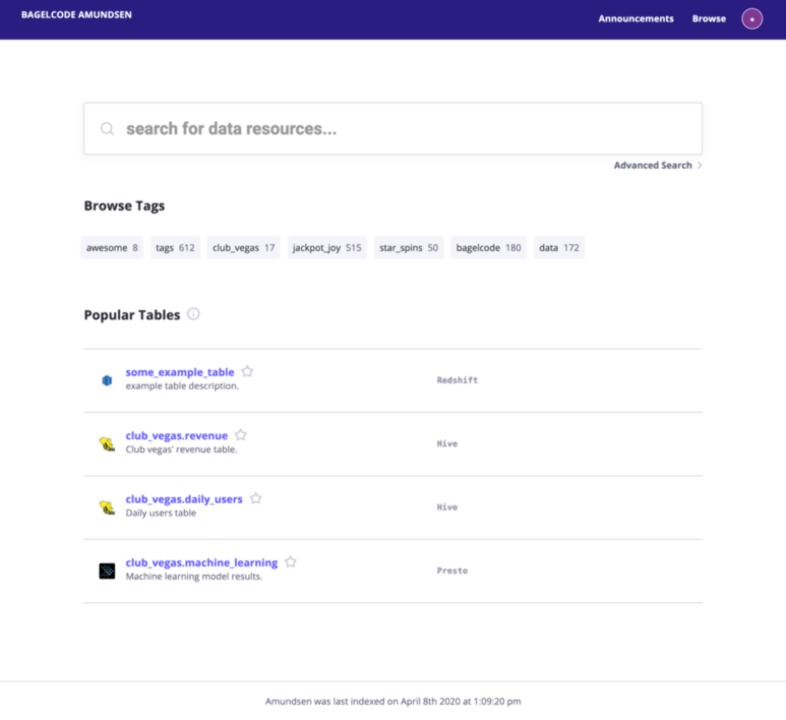
저희 데이터 디스커버리 툴은 Lyft의 오픈소스 Amundsen을 활용하고 있으며, 아래와 같이 생겼습니다.

Bagelcode Amundsen Front Page
배경
꾸준한 성장을 하고 있는 베이글코드에 쌓이는 데이터의 종류와 양은 항상 늘어만 가고 있습니다. 이는 비단 베이글코드 만의 상황이 아닌 전 세계적으로 데이터는 늘어나는 추세인데, International Data Corporation (IDC)에 따르면 2025년까지 전 세계의 데이터양이 무려 175 제타 바이트에 도달할 것이라 합니다.

Internaional Data Corporation: Annual size of the Global Datasphere
이에 따른 데이터의 폭발적인 증가가 야기하는 두 가지 문제점은:
생산성 데이터의 양과 종류가 늘어갈수록, 새로운 머신러닝 모델을 만들 때나 adhoc 분석 등을 할 시 어떤 데이터를 봐야 할지 알기 힘들어집니다. 특히 신규 입사자분들의 경우에는 베이글코드의 거대한 데이터 구조를 파악하는 데 오랜 시간이 걸립니다.
커뮤니케이션 새 테이블 추가, 스키마 변경과 같은 소통이 필요한 경우가 늘어납니다. 데이터 사용자가 적었을 때는 Slack을 통한 소통이 가능했지만, 이는 당연히 scalable 한 방법은 아닙니다.
이러한 문제점들의 해답은 데이터가 아닌 ‘메타데이터’에 있다고 판단했습니다. 이제 저희가 어떻게 베이글코드의 빅데이터가 야기하는 위의 문제들을 메타데이터를 사용하여 해결했는지 설명하고자 합니다.
Metadata
먼저 메타데이터(Metadata)의 정의는,
a set of data that describes and gives information about other data.
위와 같습니다. 데이터를 설명해주는 데이터라고 할 수 있죠.
메타데이터가 제공하는 정보들
메타데이터가 제공하는 정보는 크게 세가지의 카테고리로 나눌 수 있습니다.
맥락 — 사람이 이해하는데 도움을 주는 정보들. 예를 들어, 데이터의 존재 여부, 설명, 태그 등
행동 — 데이터가 어떻게 생성되고, 사용되는지 알려주며, 데이터 오너십, 데이터 사용자, 등의 데이터
변화 — 해당 데이터가 어떻게 변화 했는지를 보여주는 데이터. 대표적인 예로, 스키마 변화
위의 세가지 카테고리는 Joe Hellerstein, Vikaram 의 논문 Ground에서 소개된 적이 있습니다.
2. 메타데이터가 설명해주는 데이터
위에서 설명한 메타데이터가 어떤 것을 알려주는지 봅시다. 일단 메타데이터는 베이글코드 내의 모든 데이터에 관한 정보를 줍니다. 더 자세하게 이야기하자면:
데이터 저장소 — Hive, MySQL, Redshift, etc
대시보드 — Tableau 대시보드, BI 관련 정보
스트림 — Apache Kafka, AWS Kinesis 스트리밍 정보
Processing — ETL jobs, ML workflow
사람들 — 베이글코드 내의 사람들
자 그럼 위의 내용들을 요약하자면, 메타데이터는 여러 가지 데이터 저장소, 대시보드, 스트림, 등에서 나온 맥락, 행동, 그리고 변화에 관련된 정보를 제공합니다. 이 정보들을 취합한 뒤 쉽게 접근할 수 있는 형태로 바꾼다면 앞에서 설명한 생산성 문제를 해결할 수 있을 겁니다.
데이터 사이언스 Workflow
본격적으로 Amundsen을 알아보기에 앞서, 데이터 사이언티스트가 어떤 방식으로 일을 진행하는지 알아봅시다.

Data Mentor: What is Data Science?
위의 다이어그램은 일반적인 데이터 사이언스 프로세스에 관해 설명해 주고 있습니다. 가장 먼저, 비즈니스에 도움을 줄 수 있는 흥미로운 주제를 찾는 것부터 시작해 관련 데이터를 얻어, 탐색한 뒤, 모델링 또는 시각화하고, 마지막으로 결정권자들에게 분석 결과를 소통합니다.
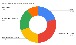
Data Science Work Time Spent
베이글코드의 데이터 사이언티스트 분들에게 한 설문 결과, 데이터 사이언스 프로세스 중 data discovery에 약 20%의 시간을 사용한다고 합니다. Data discovery의 시간을 앞서 설명한 메타데이터를 잘 사용한다면 줄일 수 있다 판단하였습니다.
Amundsen
이제 본격적으로 Amundsen에 대해 알아보겠습니다.
Webpage

Front Page

Search Result Page

Table Description Page
Amundsen 웹은 위와 같이 생겼습니다. 초기 화면은 검색 바, 태그, 그리고 자주 쓰이는 테이블을 나열해 줍니다. 검색 화면에는 검색 결과들이 relevance & popularity로 정렬되어 있습니다.
테이블 상세 설명 페이지에는
테이블 이름 및 설명
컬럼 이름, 설명, 타입
마지막 업데이트 시간
테이블 오너
자주 사용하는 유저
태그
북마크
와 같은 정보들을 볼 수 있습니다. 게다가 이런 정보들은 유저들이 직접 수정을 할 수도 있습니다. 새로운 태그를 만들거나, 설명을 추가 및 수정도 가능합니다.
Amundsen 사용후기
생산성
Amundsen 전에는, 데이터에 관한 질문이 있었다면 Slack에서 물어보는 수밖에 없었습니다.
- 안녕하세요, 게임 내 유저들의 국가 별 레이턴시를 보려면 어떤 테이블을 보면 되나요?
- 테이블 A는 언제 마지막으로 업데이트되었나요?
- 업데이트 주기는 hourly인가요?
하지만 이제 데이터에 관한 질문에 대한 해답을 대부분 Amundsen에서 찾을 수 있게 되었습니다. 질문자도 Slack 답변을 기다리지 않아도 되며, 답변자도 각자 일에 집중할 수 있게됨에 따라 모두의 생산성에 도움을 줍니다.
데이터 민주화
Amundsen은 액세스 권한이 있는 모두가 테이블에 설명을 추가하거나, 태그를 추가할 수 있습니다. (물론 이러한 수정들을 로그로 남겨, 의도치 않은 수정은 롤백이 가능하게 했습니다.) 그렇기에 시간이 지날수록 점점 많은 양의 메타데이터가 추가될 예정이며, 미래에는 데이터에 관한 모든 정보를 가지고 있는 베이글코드 데이터 위키가 되기를 기대하고 있습니다. 위키를 통하여 최대한 많은 사람들이 데이터를 통하여 의사결정을 할 수 있게 되기를 바랍니다.
베이글코드 데이터 플랫폼 유저 분들 모두 Amundsen에 긍정적인 반응을 보이셨고, 이를 증명하듯 Amundsen의 트래픽은 나날이 늘어가고 있습니다.
Engineering
Backend
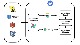
Amundsen Architecture
Amundsen은 Search, Frontend, Metadata, Databuilder로 이루어져 있는 REST API 마이크로 서비스이며, Elasticsearch와 neo4j를 백엔드 데이터베이스로 사용합니다.
위와 보시는 것과 같이, 저희는 모든 서비스들을 쿠버네티스 클러스터 위에 올려놓았습니다.
Elasticsearch & neo4j는 모두 Helm Chart를 사용하여 간단하게 설치했습니다.
Amundsen frontend를 위한 ingress를 제외하면, 모두 쿠버네티스 내부 Cluster IP를 사용해서 통신합니다.
Amundsen Metadata Ingestion
Airflow DAG에서 주기적으로 Amundsen Databuilder를 사용하여 Hive, Redshift, S3 와 같은 데이터 저장소에서 메타데이터를 추출 합니다.
추출한 메타데이터를 ETL 과정 후 Elasticsearch와 neo4j에 넣어줍니다.

Airflow DAG Example
Why Amundsen?
이미 많은 회사들은 데이터 디스커버리 툴을 사용 중입니다. Linkedin의 Data Hub, Netflix의 Metacat, Airbnb의 Data Portal, 쿠팡, 등등 많은 기업들도 데이터 디스커버리의 중요성을 공감하고 비슷한 데이터 디스커버리 툴을 사용하고 있습니다.
위의 많은 데이터 디스커버리 툴 가운데, Amundsen을 선택한 이유는 Amundsen이 가장 커뮤니티도 활발하며, 제가 좋아하는 파이썬으로 만들어져 있으며, 깔끔한 디자인이 마음에 들었습니다.
https://github.com/lyft/amundsen
마치며
빅데이터 분석의 생산성을 향상시키고, 미래에는 모두가 데이터 기반 의사결정을 내릴 수 있게 도와주는 데이터 디스커버리 툴, Amundsen에 관한 소개였습니다. 처음으로 제가 주도한 프로젝트였고, Amundsen 오픈소스 커뮤니티에도 기여할 수 있는 소중한 경험이었습니다.
이 글의 검수를 도와주신 데이터 팀 그리고 Amundsen을 잘 사용해 주고 피드백을 주시는 베이글코드 데이터 사이언티스트 & 분석가님들에게 감사의 말씀을 전합니다.
함께해요 🙂
베이글코드 데이터팀 채용공고
Reference
https://eng.lyft.com/amundsen-lyfts-data-discovery-metadata-engine-62d27254fbb9
https://www.slideshare.net/neo4j/how-lyft-drives-data-discovery-178888271
 가입하기
가입하기