Solr에서 사용할 수 있는 Search Results Clustering Engine인 carrot2 에 대해 팀내 스터디 진행하였습니다. 공부한 내용을 정리해서 작성해봤습니다. 내용은 carrot2의 소개와 carrot2에서 사용하는 clustering algorithm 중 하나인 Lingo algorithm 을 중심으로 작성하였습니다.
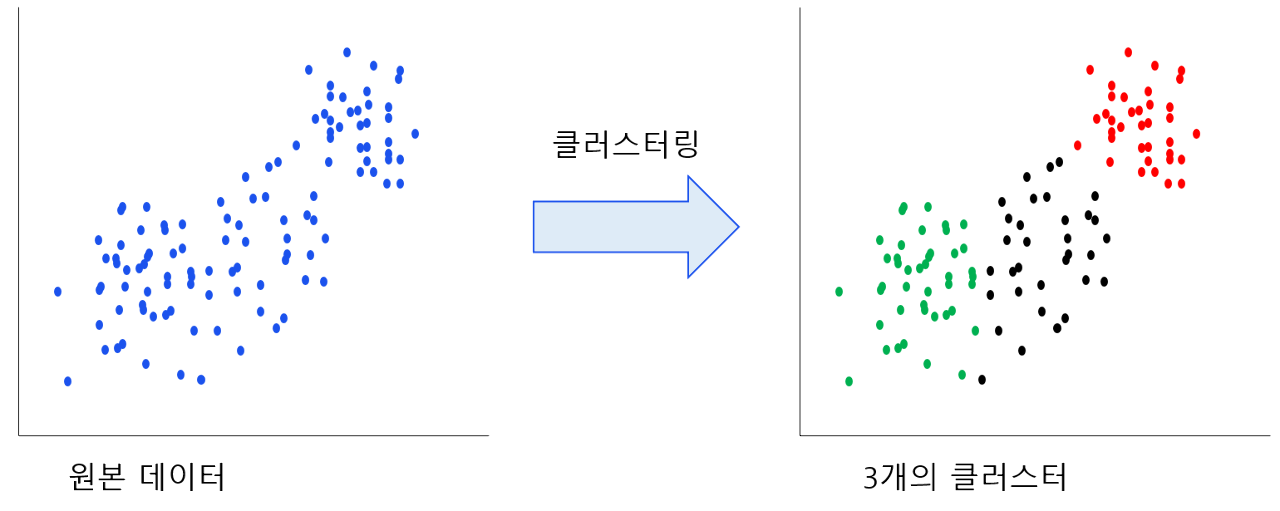
클러스터링이란?
먼저 carrot2를 설명하기 전에, 클러스터링(Clustering)이 무엇인지 간단하게 알아보겠습니다. 클러스터링은 비슷한 특성이 있는 데이터들의 집단을 만드는 작업입니다. Classification과 비슷해 보일 수 있으나 다른 개념입니다. 클러스터링은 사전 정보가 없는 데이터들을 유사도를 측정하여 비슷한 데이터를 찾아 그룹으로 만드는 개념이고 Classification은 분류해야 하는 특성을 미리 알고 있는 상태에서 데이터를 그룹화하는 개념입니다.

Solr란?
solr는 오픈소스 검색 라이브러리, Lucene을 기반으로 동작하는 검색플랫폼입니다. carrot2는 사용자가 검색한 결과 문서들을 클러스터링합니다. 즉 어떤 검색결과 문서들이 input으로 주어져야 합니다. 그러기 위해서 다양한 방법이 있지만, 이번 스터디에서는 solr를 사용했습니다.
 solr에서 검색의 과정은 위 그림처럼 이루어집니다. 검색요청이 들어오면 각 component들을 차례로 거치면서 결과를 만들어 갑니다. last component에 클러스터링을 담당하는 작업을 추가하면 검색 결과 클러스터링이 가능하게 됩니다.
solr에서 검색의 과정은 위 그림처럼 이루어집니다. 검색요청이 들어오면 각 component들을 차례로 거치면서 결과를 만들어 갑니다. last component에 클러스터링을 담당하는 작업을 추가하면 검색 결과 클러스터링이 가능하게 됩니다.
solr에 대해 더 자세히 알고 싶으면 solr reference guide에서 확인하실 수 있습니다.
Carrot2
그럼 이제 클러스터링과 solr에 대해 간략하게 알아봤으니, 본격적으로 carrot2에 대해 이야기해보겠습니다.
carrot2는 검색결과를 클러스터링해서 결과를 보여주는 데, 기존의 검색결과와는 무엇이 다른지 아래 그림을 보겠습니다.
 기존의 검색 결과는 특정한 랭킹알고리즘을 통해 결과를 보여줍니다. 예를 들어 검색 사이트에
기존의 검색 결과는 특정한 랭킹알고리즘을 통해 결과를 보여줍니다. 예를 들어 검색 사이트에 apache 라는 단어를 검색하면 apache 재단에 관련된 문서가 주로 상위에 보입니다. apache 헬리콥터나 인디언에 관련된 문서들도 있는데 상위에 보이지 않으므로 관련 문서를 사용자 입장에서는 찾기가 쉽지 않을 수 있습니다.
하지만 검색결과를 클러스터링해서 비슷한 문서끼리 그룹화한다면, 좀 더 검색 결과를 직관적으로 보여줄 수 있을 것입니다. 위 그림의 왼쪽은 기존의 검색 결과이고 오른쪽은 검색결과를 클러스터링한 결과입니다.
데모사이트에서 검색을 통해 직접 확인해 볼 수도 있습니다.
 carrot2구조는 위와 같습니다. input으로는 검색 결과가 들어오고, filter에서 클러스터링 알고리즘을 통해 비슷한 문서들끼리 클러스터를 만들게 됩니다. 생성된 클러스터들이 output이 됩니다.
carrot2구조는 위와 같습니다. input으로는 검색 결과가 들어오고, filter에서 클러스터링 알고리즘을 통해 비슷한 문서들끼리 클러스터를 만들게 됩니다. 생성된 클러스터들이 output이 됩니다.
Solr에서 Carrot2 이용해 간단한 검색하기
우선 solr에서 carrot2를 사용하기 위해서는
solrconfig.xml에 아래와 같이 설정을 해야 합니다.
- jar 포함시키기
dir="${solr.install.dir:../../..}/contrib/clustering/lib/" regex=".*\.jar" /> dir="${solr.install.dir:../../..}/dist/" regex="solr-clustering-\d.*\.jar" /> - searchComponent 추가하기
name="clustering" class="solr.clustering.ClusteringComponent"> name="engine"> name="name">lingo name="carrot.algorithm">org.carrot2.clustering.lingo.LingoClusteringAlgorithm name="engine"> name="name">stc name="carrot.algorithm">org.carrot2.clustering.stc.STCClusteringAlgorithm
- 미리 정의되어있는 알고리즘
- LingoClusteringAlgorithm (open source)
- STCClusteringAlgorithm (open source)
- BisectingKMeansClusteringAlgorithm (open source)
- Lingo3GClusteringAlgorithm (commercial)
위와 같이 미리 정의 되어있는 클러스터링 알고리즘을 carrot.algorithm 값으로 사용하면 됩니다. name은 엔진을 구별하기 위해 정의합니다.
나열된 알고리즘 중 Lingo3GClusteringAlgorithm 는 open source가 아니므로 CarrotSearch에서 구매하여 확인할 수 있습니다.
URL 파라미터로 clustering.engine=(engine name) 로 설정합니다. 엔진을 선택하여 위에 선언한 알고리즘으로 클러스터링을 진행하게 됩니다. clustering.engine 파라미터를 입력하지 않으면, 제일 먼저 선언한 엔진이 default로 설정됩니다.
- RequestHandler 만들기
name="/clustering" class="solr.SearchHandler"> name="defaults"> name="clustering">true name="clustering.results">true name="carrot.title">title name="carrot.snippet">content name="fl">*,score name="last-components"> | Parameter | Description |
|---|---|
carrot.title | 문서의 제목에 해당하는 필드를 지정, snippet으로 지정한 필드보다 더 높은 가중치를 줌 |
carrot.snippet | 문서의 내용에 해당하는 필드를 지정 |
더 자세한 파라미터와 설명은 solr reference guide에서 확인할 수 있습니다.
- 검색결과 확인하기
아래 그림은 테스트 데이터에 위와 같이 검색한 결과의 일부입니다. 결과를 통해 클러스터가 생성된 것을 확인할 수 있습니다.
 클러스터는
클러스터는
아래 그림을 통해, 결과를 직관적으로 이해할 수 있습니다. 
Lingo algorithm
Lingo 알고리즘은 carrot2를 만든 Stanisław Osiński가 만든 알고리즘입니다. 그는 Lingo 알고리즘이 다른 클러스터링 알고리즘과 차이점이 있다고 합니다.
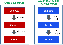
다른 대다수의 클러스터링 알고리즘은 위 그림 좌측에 있는 구조처럼 먼저 문서들간의 유사도를 비교하여 클러스터를 우선 만듭니다. 그 후 클러스터 대표할 단어를 찾아 결과를 반환합니다.
Lingo 알고리즘은 위 그림 우측에 해당하는 방법을 사용합니다. 클러스터를 만드는 일보다 먼저 문서들을 비교하여 레이블을 찾습니다. 레이블은 사용될 클러스터를 대표하는 단어및 구문이 됩니다. 즉, 클러스터를 단어 및 구문을 우선 찾는 방법입니다. 그 후, 문서들을 찾은 레이블들과 비교하여 어울리는 레이블에 문서를 넣습니다.
Lingo 알고리즘은 다섯단계로 진행됩니다.
- Preprocessing
- Feature extraction
- Cluster label induction
- Cluster content discovery
- Final cluster formation
단계별로 간단하게 살펴보겠습니다.
- Preprocessing
- 문서의 언어를 판단하고, 어간 추출(stemming) 작업을 합니다. 그리고 불용어(stop words)에 표시를 해둡니다. 한국어 불용어도
stopwords.ko라는 파일에 등록되어있습니다.
- Feature extraction
- 문서내에 자주 사용되는 단어와 구문을 추출합니다. 추출한 단어들과 구문들은 레이블 후보가 됩니다. 구문을 발견하는 작업은 접미사 배열(Suffix array)을 이용합니다. 바로 전 단계에서 불용어를 삭제하지 않은 이유는 불용어가 구문을 이해하는 데 더 도움이 될 수 있기 때문입니다.
구문Chamber Commerce와Chamber of Commerce를 비교해보면of가 불용어지만 불용어를 제거하지 않은 후자가 더 이해하기 좋은 구문입니다.
전 단계에서 삭제는 하지 않았지만, 불용어를 표시해둔 이유는 구문이 불용어로 시작하거나 끝나면 레이블로 사용하기에 적절하지 않기 때문입니다. 불용어로 시작하거나 끝나는 구문은 후보가 될 수 없습니다.
- Cluster label induction
- 후보로 선정된 단어들과 구문들을 이용해 클러스터에 사용될 레이블을 선정합니다. 특이값분해(singular value decomposition, 약자 SVD)로 잠재적인 의미를 찾을 수 있습니다.
term x Document 행렬 A를 다음과 같이 분해할 수 있습니다.
A = UΣ VT
SVD 계산법은 여기에서 확인할 수 있습니다.
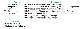 예제를 통해 어떻게 레이블을 선정하는지에 대해 알아보겠습니다. 위의 그림은 7개의 문서와 전 단계들을 거치면서 나온 term과 phrase입니다.
예제를 통해 어떻게 레이블을 선정하는지에 대해 알아보겠습니다. 위의 그림은 7개의 문서와 전 단계들을 거치면서 나온 term과 phrase입니다.
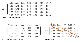 행렬 A를 이용해 행렬 U와 Σ를 구할 수 있습니다. 행렬 U는 term x abstract concept 행렬이고, Σ는 abstract concept 값(특이값)이 내림차순으로 정의된 진단행렬입니다. 여기선 abstract concept는 클러스터 레이블 후보들입니다.
행렬 A를 이용해 행렬 U와 Σ를 구할 수 있습니다. 행렬 U는 term x abstract concept 행렬이고, Σ는 abstract concept 값(특이값)이 내림차순으로 정의된 진단행렬입니다. 여기선 abstract concept는 클러스터 레이블 후보들입니다.
k를 지정하여 후보 중 일부만을 추리도록 합니다. Lingo알고리즘에서는 행렬 Σ를 k값을 구하는 데 사용합니다. k는 클러스터의 개수입니다. 구하는 공식은 아래와 같습니다.
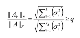 이제 행렬 M을 구합니다. 행렬 M은 아래와 같이, 두행렬의 곱으로 구할 수 있습니다. 앞서 구한 행렬 U의 k개의 열만을 사용하는 전치행렬을 행렬 P, term x (phrase + terms)와 곱하면 됩니다. 행렬 M은 클러스터 레이블 후보와 phrase+term에 관련된 행렬이 됩니다. 후보 레이블 중에 사용할 레이블을 선정하는 행렬입니다.
이제 행렬 M을 구합니다. 행렬 M은 아래와 같이, 두행렬의 곱으로 구할 수 있습니다. 앞서 구한 행렬 U의 k개의 열만을 사용하는 전치행렬을 행렬 P, term x (phrase + terms)와 곱하면 됩니다. 행렬 M은 클러스터 레이블 후보와 phrase+term에 관련된 행렬이 됩니다. 후보 레이블 중에 사용할 레이블을 선정하는 행렬입니다.
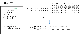 행렬 M의 행의 수가 클러스터 수가 됩니다. 첫 번째 행은 클러스터1에 대한 행이 됩니다. 첫번째 열은 Phrase1, Singular Value가 됩니다. 각 값은 클러스터와 단어및 구문의 유사 정도라고 생각하시면 됩니다. 값이 높을 수록 해당 클러스터를 설명하는 단어및 구문이 됩니다. 즉 클러스터1에 해당하는 레이블은 가장 첫 번째 행에서 가장 높은 값인 0.92를 가진 Phrase1인
행렬 M의 행의 수가 클러스터 수가 됩니다. 첫 번째 행은 클러스터1에 대한 행이 됩니다. 첫번째 열은 Phrase1, Singular Value가 됩니다. 각 값은 클러스터와 단어및 구문의 유사 정도라고 생각하시면 됩니다. 값이 높을 수록 해당 클러스터를 설명하는 단어및 구문이 됩니다. 즉 클러스터1에 해당하는 레이블은 가장 첫 번째 행에서 가장 높은 값인 0.92를 가진 Phrase1인 Singular Value가 됩니다. 클러스터2는Information Retrieval이 됩니다.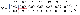 이제 2개의 클러스터를 찾았고 각 클러스터를 설명할 수 있는 레이블도 찾았습니다.
이제 2개의 클러스터를 찾았고 각 클러스터를 설명할 수 있는 레이블도 찾았습니다.
- Cluster content discovery
- 벡터 공간 모델을 이용해 검색결과 문서들을 클러스터에 할당합니다.
- Final cluster formation
- 클러스터의 점수를 측정하고 병합해야될 클러스터는 병합을 합니다. 점수를 계산하는 방법은 아래와 같습니다.
cluster-score = label-score x member-count
마무리
지금까지 carrot2에 대해 알아보았습니다. carrot2는 사용하기도 용이하고 꽤 괜찮은 결과를 보여주는 것 같아 보였습니다. 하지만 결과와 성능 측면에서 개선해야 할 점이 보였습니다.
1.결과
결과는 label로 선정된 구문에 대한 이야기입니다.
 위 그림은 apache 로 검색한 결과 중 생긴 클러스터입니다. 위 그림 우측은
위 그림은 apache 로 검색한 결과 중 생긴 클러스터입니다. 위 그림 우측은 stopwords.ko 파일 일부입니다. 파일 안에 할 수 있는이 들어 있지 않은 것을 확인할 수 있습니다. 이렇듯 stopwords.ko 파일에 등록되어 있지 않은 불용어로 시작하거나 끝나는 구문이 label로 지정되는 경우가 종종 생겼습니다. 할 수 있는이 apache 로 검색한 결과 내에서 의미 있는 구문은 아니기에 원하지 않는 결과입니다.
2.성능
| 검색 수행 사용자 | 테스트 진행 시간 |
|---|---|
| 40 | 30min |
위와 같은 조건에서 기존 검색 과 carrot2의 Lingo 알고리즘을 이용한 검색 , 총 두 가지 검색을 검색반환 문서 수(10, 20) 에 따라 진행하였습니다.
아래 그래프는 테스트에 관한 결과를 TPS(transaction per second) 그래프 입니다. x축은 경과 시간(초)을 나타내고 y축은 TPS를 나타냅니다. TPS는 초당 transaction을 처리한 수를 나타내는 데, 이 테스트에서 transaction은 검색하고 결과를 반환받는 과정을 말합니다. 즉 TPS가 높을수록 성능이 좋다고 말할 수 있습니다.
 그래프에는 총 4가지 선이 존재합니다. default는 기존 검색을 의미하고, Lingo는 carrot2를 이용한 검색을 의미합니다. row는 검색 반환 문서의 수를 의미합니다. Lingo 알고리즘에서 검색반환 수가 25인 경우가 가장 낮은 TPS를 보이는 것을 확인할 수 있습니다.
그래프에는 총 4가지 선이 존재합니다. default는 기존 검색을 의미하고, Lingo는 carrot2를 이용한 검색을 의미합니다. row는 검색 반환 문서의 수를 의미합니다. Lingo 알고리즘에서 검색반환 수가 25인 경우가 가장 낮은 TPS를 보이는 것을 확인할 수 있습니다.
| Lingo / row=25 | Lingo / row=10 | default / row=25 | default / row=10 | |
|---|---|---|---|---|
| 평균 응답 시간 (ms) | 283.4 | 133.1 | 48.5 | 40.7 |
| 평균 TPS | 140.9 | 299.9 | 820.7 | 977.3 |
테스트를 통해 carrot2를 이용한 검색이 기존의 검색보다 성능이 낮은 것을 확인했습니다.
검색에서 실시간 클러스터링을 사용하기 위해서는 정확도와 응답속도 개선이 필요해 carrot2의 대대적인 커스터마이징이 필요할 것으로 판단됩니다.