안녕하세요. Humanscape Software Engineer David 입니다.
서비스를 운영하는 팀에서는 늘 안정적이게 (High Availability, HA) 서비스를 운영해야하는 임무가 있습니다.
유저가 다운 타임 및 오류를 겪으면 안되니 필수적으로 다양한 유저의 행동에 대해 QA를 진행하게 되고, 비지니스 로직과 서비스 특성에 맞게 아키텍처를 구성하고, 서버의 하드웨어 스펙을 정하기도 합니다.
대부분의 스타트업이 데이터 센터가 아닌 클라우드 서버를 이용하는 이유이기도 합니다. 스타트업이 서버를 온전히 운영하기에는 리소스가 많지 않기 때문이지요.

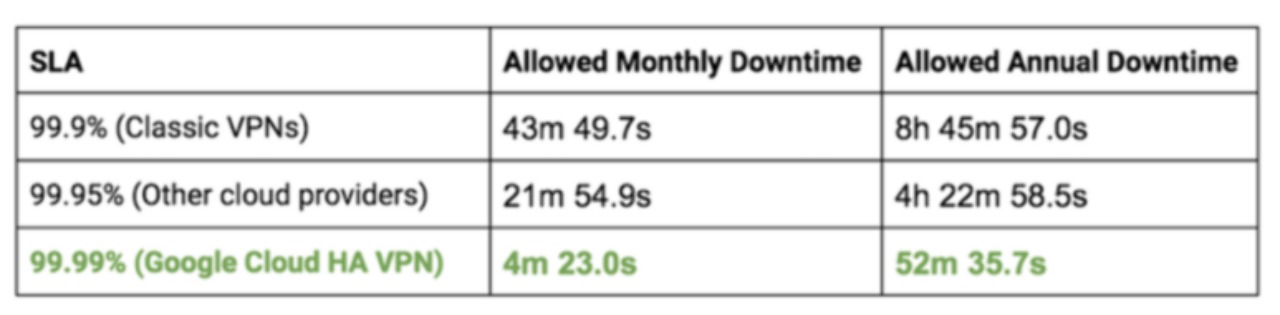
가용성 수치 비교(https://gc.hosting.kr/security-ha-vpn/)
이는 서비스 개발팀이 각자의 위치에서 치열하게 고민하는 부분인데요.
QA(QE, TE): 서비스의 품질 향상을 위한 기획, 개발적 오류 발견, 수정, 추적 (ex. 2월 29일에 태어난 유저에게 생일 쿠폰을 어떻게 주어야 할까, 미국에서 핸드폰 언어를 한국어로 쓰는 미국인에게는 어떤 언어로 서비스되어야할까, 한 사람이 여러 계정으로 가입해 포인트를 모을 수 있는 현상 포착 -> 대응)
Server side Engineer: 비지니스 로직 및 서비스 특성에 맞게 Server side 인프라 구축 (ex. 알람 어플의 경우에는 오전 6~8시, 네이버 웹툰의 경우 오후 11시와 같이 트래픽이 몰리는 시간에 한시적으로 클라우드 서버의 스펙올리는 방식으로 flexible 하게 가져간다고 함), 중국에 서비스를 해야한다. 😱
DBA(Database administrator): DB 성능 트래킹, 백업 및 재난 복구 계획 수립(ex. 윤초 발생 시 대응은?)
그렇다고 하더라고 오류는 발생하게 됩니다.
이유1. 소프트웨어도 녹이 슨다.
정말 버그가 0인 제품이 있다고 하더라도 소프트웨어는 여러가지 외부 요인의 영향을 받을 수 있습니다. 우리가 사용하는 API가 서비스를 종료한다던지, 올해 윤초 발생을 잊고 있었다던지, 크롬 기반으로 쿠키를 사용하는 서비스인데 크롬이 쿠키 정책을 바꾼다던지. 대응하지 않으면 서비스를 멈추게 할 이유는 너무나 많습니다.

최근 휴먼스케이프 미세톡톡팀에게 도착한 오픈API 폐기 소식
이유2. 요구사항은 멈추지 않는다.
졸업 설계 프로젝트, 공모전 제출 목적의 Project가 아닌 서비스로 운영되는 Product는 요구사항이 멈추지 않습니다.
페이스북, 유튜브 초기 모습
유튜브의 최근 모습을 보면 프로덕트는 정말 수많은 요구사항으로 완성되어 나가는 거 같다는 생각이 드네요. 😅
오류가 늘 존재할 수 있다는 절망적인 사실은 알겠습니다.
그럼 두 가지가 중요합니다.
알림: 서비스에서 오류가 발생하면 개발팀이 가장 먼저 오류를 리포팅 받는게 중요합니다. 유저의 컴플레인에 대응할 시간을 벌어주기도 하고, 누구보다 빠르게 알아야 오류 수정까지의 시간이 줄어들고 줄어든 시간만큼 오류를 겪는 유저의 수도 줄어들게 됩니다.
대응 프로토콜: 알림을 받는 시스템만 구축되어있어 ‘ 🔔오류 발생🔔' 과 불친절하게 같이 알려준다면 누가 오류를 확인해야할지 애매한 상황이 발생하게 되고, 또 오류는 다양하고 예측을 할 수 없기 때문에 파악하는데 오래 걸릴 수 있습니다. 그렇기 때문에 오류를 파악할 수 있는 단서가 많은 상세한 오류 알림과 오류 발생시 대응에 대한 프로토콜이 구축되어있어야 빠르게 대응할 수 있습니다.
휴먼스케이프는 오류에 어떻게 대응하고 있을까요?
Newrelic (APM, INFRASTRUCTURE), GCP Stackdriver, Firebase (Crashlytics) 로 오류를 트래킹 할 수 있도록 세팅 되어있지만 알림 기능으로 다양한 플랫폼을 지원하고 많은 기능을 제공해주고 있는 Sentry와 사내 메신저인 Slack을 적극 이용하고있습니다.
Sentry 뭐가 좋나요?
다양한 플랫폼 지원

모바일, 데스크탑, 서버 등 다양한 platform을 지원하는 Sentry
위 그림에서 Other로 프로젝트를 생성하면 다시 platform 선택 화면으로 넘어가네요.
보통 서비스를 개발할 때 다양한 플랫폼을 사용하게 됩니다. 스타트업의 경우 개발인원이 많지 않다보니 최대한 스택을 단순하게 가져가려 하는데요.
처음에 단순하게 기술 스택을 구성해놓아도, 외부 서비스 연동이나 새로운 기능 구현 시 어쩔 수 없이 스택은 늘어나는 상황이 발생하게 됩니다.
대부분의 플랫폼을 지원하고 있는 Sentry는 비지니스 로직이 확장 되어도 에러 모니터링을 일원화 할 수 있다는 장점을 가지고 있습니다.
다양한 알림 연동 지원
Azure DevOps, Bitbucket, GitHub, GitHub Enterprise, GitLab, JIRA, JIRA Server, PagerDuty, Slack
Amixr, ClickUp, Clubhouse, Rookout, Split
Amazon SQS, Asana, Campfire*, Flowdock, GitLab, Heroku, HipChat, Lighthouse*, OpsGenie, PagerDuty, Phabricator, Pivotal Tracker, Pushover, Redmine, Splunk, Taiga, Teamwork, Trello*, Twilio
알림 연동 또한 다양한 플랫폼을 지원합니다. 이게 가능한 이유는 Sentry에서 외부 서비스가 REST API 및 Webhooks 를 사용하여 Sentry SaaS 서비스와 상호 작용할 수 있는 방법을 제공 하기 때문입니다.
오류를 파악할 수 있는 다양한 정보 제공
Device: 오류가 발생한 장비 정보 (Family(Android, iOS … etc), Model, Architecture, Memory, Capacity, Simulator, BootTime, Timezone)
App: 오류가 발생한 어플리케이션 정보 (ID, Start Time, Device, Build Type, Bundle ID, Bundle Name, Version, Build)
Browser: 오류가 발생한 브라우저 정보 (Name, Version, Headers)
Operating System: 유저가 사용하는 OS (Name, Version, Kernel Version, Rooted)
BREADCRUMBS: 유저가 오류에 도달하기 까지의 경로
EXCEPTION: 에러가 발생한 코드 라인과 에러 메시지
개인적으로 토이프로젝트에 사용하고 있는 무료 버전을 기반으로 주요한 정보를 살펴보았습니다. 무료인데도 오류를 파악하는데 무리가 없을 정도로 많은 정보를 제공해주고있네요. 👍
무료도 많은 기능을 제공해주지만 아래와 같은 제한이 있습니다.
하나의 계정만 사용 가능: Sentry는 브라우저, 앱, 서버 등 다양한 플랫폼에서 이용하게 되는데 관련자들의 권한을 설정할 수 없고, 모두 하나의 비밀번호를 공유하게 됩니다. 보안에 필수요소인 2FA도 현실적으로 사용하기 어렵습니다.
리포팅 개수 제한: 동접 10,000 인 서비스가 있고 로그인에서 오류가 발생했다고 하면, 로그인 에러는 100% 에 가깝게 영향을 주기 때문에 10,000 개의 오류가 리포팅 되게 됩니다. Sentry 의 장점 중 같은 오류가 여러번 발생하면 알림은 시간 단위로 한번씩만 오도록 설정(Intelligent deduplication)할 수 있어 알림을 10,000 번 받는 상황은 피할 수 있지만, 무료 버전은 리포팅이 한달에 5000개로 제한 되어있어 규모에 맞게 pricing 설정이 필요합니다.
레포지토리 설정 불가: Sentry는 디버그 파일을 사용하여 스택을 추적하여 추출하고 이슈에 대한 자세한 정보를 제공합니다. 디버그 파일에 저장된 함수 명, 소스 코드 또는 메모리에 변수 배치 등이 포함됩니다. 무료 Sentry는 레포지토리 설정을 할 수 없어 디버그 파일에 대한 추적이 불가능 하지만, Team 이상의 plan으로 비용을 지불하면 디버그 파일에 대한 이슈 세부 사항 페이지도 볼 수 있습니다.
환경 별 구성은 어떻게 해야할까요?
Local / Development 환경: 개발할 때 보통 알림이 너무 많이 오게 되므로 Sentry Local 개발환경의 경우 Sentry의 필터링 기능으로 로컬 포트에 대한 알림을 필터링할 수 있습니다. Development 환경의 경우 IP 기반으로 특정 개발 서버의 IP를 설정하여 알림이 울리는 것을 제어할 수 있습니다.
Staging 환경: 개발 환경은 아직 불안정 하므로 슬랙 채널의 알람을 꺼 놓기도 합니다. 단, 모든 오류는 추적되어야 하고 고쳐서 Production 환경에 배포되어야 하기 때문에 Sentry DSN 설정 자체를 꺼 놓으면 안됩니다.
Production 환경: 모든 알림을 트래킹해야합니다. 근무 시간 외 혹은 새벽에 사내 메신저 알림을 꺼 놓는게 좋지만 알람 채널만은 꺼 놓으면 안됩니다. 슬랙 등 업무용 메신저는 타임존에 맞게 새벽 알림이 자동으로 울리지 않게 되어있는 경우가 있습니다. Production 알림의 경우는 새벽에도 받을 수 있도록 켜 놓아야합니다.
알림 대응 프로토콜이 있어야합니다.
프로토콜이 없어서 고민 중 이모지만 달고 아무도 건들지 않고 있는 예시 이미지
오류에 알림에 익숙해져버려 팀원 Hugh를 당황하게 하고 뒤늦게 모든 오류를 파악하는 David의 잘못된 예시 이미지
위와 같은 상황을 방지하기 위해 경각심을 갖고 보고 된 오류에 대해서는 이모지, 스레드를 활용해 업무를 진행합니다.
Reaction emoji: 담당자와 진행상황이 표시되어야합니다.
Reply thread: 오류 추적에 대한 모든 내용이 기록 되어야합니다. 스레드가 아닌 채널 채팅을 통해 직접 소통할 경우 에러 알림과 헷갈릴 수 있고, 어떤 오류에 대한 내용인지도 불명확해질 수 있습니다.
담당자 표시: 휴먼스케이프는 팀원들 마다 이모지가 있기 때문에 나다 싶으면 Sentry의 담당자를 지정하고 오류 파악을 시작합니다. 혹 담당자가 애매할 경우 Reply thread 혹은 오프라인에서 정한 뒤 담당자를 설정해줍니다.
진행상황 표시: 담당자가 설정 된 오류는 진행 중 상태로 인식합니다.오류 파악, 진행에 대한 기록을 Reply thread에 남겨둡니다.
오류 파악 완료 후 : 해당 오류를 수정하기 위해 필요한 작업은 Dooray!(협업 툴)에 이슈 티켓으로 등록해줍니다. PM이 중요도를 판단해 담당자와 작업의 우선순위를 설정하게 되어 처리되게 됩니다.
오류를 파악하고 완료: Slack의 이슈에 resolve -> immediately 로 오류를 완료 처리합니다.
그밖의 알아두면 좋은 Sentry의 기능들
IP 필터링: 사무실, 개발 서버 등 특정 IP를 설정하여 알림 필터링
Lagacy 브라우저 설정, Local 개발 환경 알림 설정
이번 포스팅으로 안정성 높은 서비스를 개발하기 위해 오류 발생 시 대응에 대해 Sentry를 통해 알아보았습니다.
Sentry는 ‘보초'라는 그 단어의 의미처럼 강력하고 스마트하게 오류를 잘 감시하는 친구인 거 같습니다.
다음 포스팅에서는 안정성 높은 서비스 개발하기 두 번째로 Newrelic APM(Application Performance Manager) 및 Newrelic INFRASTRUCTURE 에 대해 알아보도록 하겠습니다.
감사합니다.
Telegram(EN) : t.me/Humanscape KakaoTalk(KR) : open.kakao.com/o/gqbUQEM Website : humanscape.io Medium : medium.com/humanscape-ico Facebook : www.facebook.com/humanscape Twitter : twitter.com/Humanscape_io Reddit : https://www.reddit.com/r/Humanscape_official Bitcointalk announcement : https://bit.ly/2rVsP4T Email : [email protected]
 가입하기
가입하기