휴먼스케이프 Software engineer Covy입니다.
본 포스트에서는 semantic segmentation 분야에서 인용 수 54000+을 육박하는 논문에 대해서 리뷰하려고 합니다. 특히 이 논문은 deep neural network의 학습 효율에 대한 기여로 CVPR 2016에 실렸습니다. 논문의 제목은 다음과 같습니다.
“Deep Residual Learning for Image Recognition”
논문에 대한 내용을 직접 보시고 싶으신 분은 이곳을 참고하시면 좋습니다.
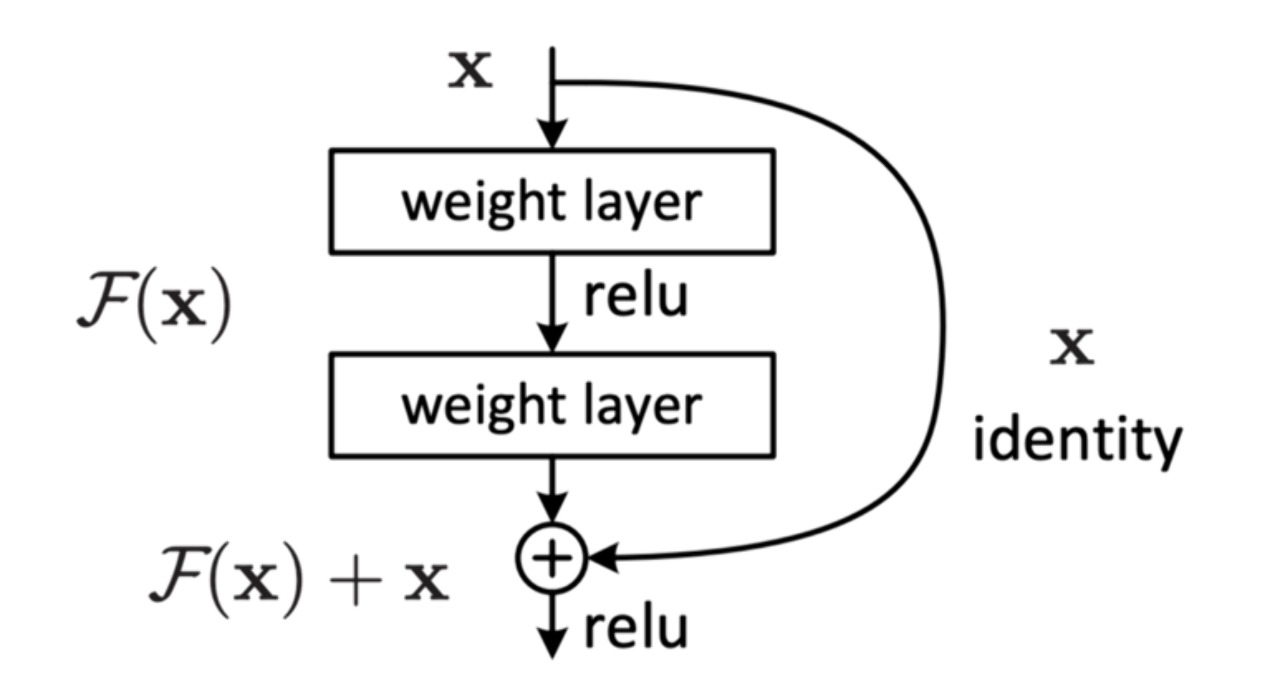
Basic concept of Residual Learning
Objective
논문에서 목적으로 하고 있는 것은 deeper neural network 구조에서 나타나는 gradient vanishing 현상으로 인한 degradation(학습효과 저해)을 해결하는 것입니다.
일반적으로 gradient vanishing은 신경망이 깊어짐에 따라서 layer의 한 weight 값이 전체 연산 결과에 영향을 미치는 정도가 굉장히 작아지는 현상을 말합니다. 이는 neural network에서 사용하는 activation function이 미분을 거치게 되었을 때 나오는 output의 scale이 줄어든다는 점 때문에 발생하게 됩니다. 즉, back propagation을 진행할 때 오류 항목에 지속적으로 activation function의 미분 항이 포함되면서 실제 output layer로부터 먼 쪽(초기 layer)의 경우, 그 오류의 scale이 굉장히 작아지면서 gradient descent가 실제 output에 반영되기 힘든 구조가 되는 것입니다.
흔히 이런 deep neural network에서 나타나는 학습효과 저해를 overfitting(특정 데이터셋의 특성을 과도하게 반영하여 일반적으로 에러가 커지는 현상)에 의한 것으로 단순히 해석하고 넘어갈 수 있는데, 논문에서 초점을 맞추고 있는 현상은 이러한 원인이 아니라는 것을 명확히 짚고 넘어갑니다.

reason why the problem is not caused by “overfitting”
Overfitting이 원인인 학습효과 저해의 경우, training error는 작지만 test error는 크게 등장해야 합니다. 하지만, 양쪽 그래프의 경우 모두 layer 수가 더 많은 쪽이 error가 크게 등장한다는 것을 통해, 일반적으로 깊은 신경망에 대한 학습효과 저해에 초점을 맞추고 있다는 것을 보여줍니다.
Residual Learning
앞에서 설명드린 degradation 현상은 복잡한 layer를 추가하지 않고 단순히 identity layer 만을 기존의 신경망에 붙이더라도 발생했던 현상입니다. ResNet은 이런 identity mapping을 조금 더 잘 구현할 수 있는 방법으로 residual learning을 제시합니다.
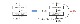
plain net VS residual net
기존에 존재했던 neural network는 좌측의 plain net의 구조로, input x에 대해서 목표로 하는 H(x)를 학습하는 것을 목적으로 합니다. 반면, residual net 구조는 input x 에 대한 목표 H(x)에 identity mapping인 x를 포함시킨 형태로 남은 F(x)를 optimize하는 형태를 가지고 있습니다.
Identity mapping의 관점에서 위 구조를 살펴보면 좌측의 plain net은 H(x)를 x와 동일하도록 학습시켜야 하는 반면, 우측의 경우 F(x)=H(x)-x를 0에 수렴하도록 학습시켜야 함을 알 수 있습니다. layer를 특정 값 input x를 가지도록 학습시키는 경우보다는, 어떤 x가 들어오더라도 residual(잔차)를 0을 가지도록 학습하는 것이 더욱 좋은 학습효과를 불러올 것이라는 것에서 시작한 발상입니다.
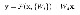
general residual formula
덧붙여, 앞서 설명한 residual net을 위와 같은 형태의 식으로 나타낼 수 있습니다. 여기서 W_s의 경우, input과 output의 dimension이 동일하지 않을 경우, 맞춰주기 위한 linear projection matrix입니다.
How Residual Learning Solves Problem
다중 layer를 이용한 identity mapping의 구현의 용이성이라는 관점에서 시작했지만, residual learning은 근본적으로 degradation의 문제를 해결하기에 적합했습니다.
이는 H(x) 항목에 고정적으로 linearly addition된 x가 결과적으로 output layer에서 먼 layer에서도 output에 대한 x값 반영이 용이하게 일어나도록 작용하기 때문입니다.
이러한 각 layer의 feature 의 output에 대한 반영에 대한 측면으로 ResNet의 효율적인 측면을 분석한 “Identity Mappings in Deep Neural Networks” 논문에 대해서도 한 번 읽어보시면 좋을 것 같습니다. 논문에서 제시한 내용에 대해서 간략히 소개하면 다음과 같습니다.
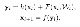
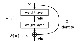
residual net connection
먼저 residual net에서 형성한 block에 따라서 위와 같은 식으로 input-output의 mapping을 형성할 수 있습니다. 여기서 h는 shortcut-connection을 제공하는 함수이며, F는 weight와 feature로 계산된 항목입니다. 더불어 f는 activation function입니다.
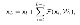
feature mapping between two layer
이후 논문에서도 등장하겠지만, h를 identity mapping으로 설정하는 것이 일반적으로 좋은 성능을 보이며, activation function 또한 ReLU등의 함수를 사용했을 경우를 반영한 identity로 가정하고 수식을 전개하면 위와 같은 형태로 나타나게 됩니다. 이 수식에서부터 feature의 온전한 전달이 이루어진다는 느낌을 강하게 받을 수 있습니다.
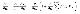
error backpropagation
특정 layer의 feature가 기여하는 error 항목을 구하면 위와 같이 나타납니다. 앞서서 feature간의 관계를 나타낸 forward propagation식을 이용해 전개를 한 결과입니다. 여기서 주목해야 할 것은 식의 첫 번째 항입니다. 이 값은 layer의 깊이에 관계없이 일정하게 backpropagation을 통해 전달되는 값입니다. 결과적으로 최소한의 gradient를 보장해 줌으로써 feature에 대한 error를 일정 수준으로 유지할 수 있고, 이를 통해서 각 weight가 total output에 기여하는 정도도 일정수준 이상으로 유지할 수 있게 되는 것입니다.(이 부분에 대한 이해가 잘 되지 않는다면 backpropagation formula에 대해서 보고 오셔도 좋습니다)
Deeper Bottleneck Architecture
이렇게 깊은 신경망을 구현하면 복잡해진 신경망 구조만큼 많은 양의 연산이 필요하게 됩니다. GoogleNet은 이러한 점을 이용해 Inception v1이라는 기술을 사용해 연산의 수를 대폭 줄이면서도 성능을 어느정도 유지하는 방안을 제시합니다. ResNet에서는 이러한 구조를 반영하여 기존의 residual net block의 양 끝에 1x1 convolutional layer를 붙여서 feature의 depth를 줄인 후 연산을 거친다음 다시 늘리는 형태를 구현했습니다. (연산 횟수에 대한 계산 내용은 단순 생략하겠습니다.)
Inception v1
Experiment 1 : ImageNet
CVPR에 게재된 논문답게, 논문에서는 구현한 네트워크에 대한 다양하고 세심한 실험들을 통해 제시한 구조가 일반적으로 효율을 개선하는 것에 유의미한 결과를 가져온다는 것을 증명합니다.

ImageNet
가장 먼저 논문에서 제시한 것이 ImageNet 2012 classificaiton dataset을 이용해서 VGG-19 net을 참고하여 34-layer plain net과 34-layer residual net을 설계하여 비교한 성능입니다.

plain net VS residual net
위 그래프는 iteration에 따른 error를 나타낸 그래프입니다. 그래프에서 얇은 선이 training error 이고, 굵은 선이 validation error입니다.
먼저 좌측 그래프의 경우 PlainNet 만을 나타내는데, degradation problem이 나타난 것을 확인할 수 있었습니다. 그런데, 논문에서 확인한 바에 따르면 실제로 gradient 값을 확인해본 결과 gradient vanishing으로 볼 만큼 작지 않았기 때문에 gradient vanishig에 의한 degradation은 아닌 것으로 보고 있습니다. 이러한 optimization difficulty 에 대해서는 추후의 연구로 미루고 있습니다.
다음으로 우측 그래프의 경우 ResNet을 나타내는데, 깊은 신경망 구조에서의 error가 더 작게 나타났다는 사실을 볼 수 있었습니다.
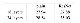
top 1 error
Top 1 error의 관점에서도 ResNet이 PlainNet 보다 더 좋은 학습효과를 나타냈다는 사실을 알 수 있습니다. 이 결과는 모든 shortcut connection의 increasing dimension에 대해 zero padding을 진행한 결과입니다. 이를 통해 residual net을 이용해 degradation problem을 해결한 것으로 보고 있습니다.
마지막으로 18 layer PlainNet과 18 layer ResNet에 대해서는 PlainNet과 ResNet 이 비슷한 수준의 error로 수렴했지만, ResNet이 앞서 제시한 optimization(특정 값으로의 학습이 아니라 잔차를 0으로 보내는)을 쉽게 하여 훨씬 더 빠르게 수렴지점에 도달했다는 사실을 알 수 있었습니다.
Experiment 2: Dimension Increasing Option & Deeper Bottleneck Architecture
앞서 설명한 Deeper Bottleneck Architecture를 이용해서 논문에서는 ResNet-50, ResNet-101, ResNet-152등의 네트워크 구조를 만들어 평가합니다. 또한 dimension increasing(앞서 설명한 W_s를 사용한 dimension 변화가 존재할 경우의 방법)을 위한 경우의 수로 3가지 방법을 제시하여 각각의 경우에 대한 성능을 평가합니다.

dimension increasing option & deeper bottleneck architecture
3가지 방법 A, B, C 는 각각 dimension increasing을 위해 zero padding을 사용하기, dimension increasing이 필요한 경우에만 projection shortcut 사용하기, 모든 경우에 projection shortcut 사용하기 였습니다. 결과 상으로는 C, B, A 순서로 높은 성능을 보였지만, 논문에서는 큰 차이를 보이지 않는 것으로 보고 모델을 복잡하게 만들지 않기 위해서 C의 경우는 배제하게 됩니다.
50-layer ResNet의 경우는 기존 34-layer에서 2-layer block으로 구현된 residual block을 일부 3-layer residual block으로 바꾸었고, 101, 150 또한 50보다 더 많은 block을 바꾸어 layer수를 늘렸습니다. 이 경우들 전부 degradation problem을 관찰할 수 없었고 더 좋은 성능을 보임을 확인할 수 있었습니다.
여기서 직접적으로 데이터를 제시하지 않겠지만, 논문에서는 위 구조들을 조합해서 ImageNet validation을 진행한 결과 최종적으로 top 5 error 3.57%의 더 나은 성능의 구조를 만들 수 있었다고 합니다.
Experiment 3: CIFAR-10 dataset
다음으로 논문에서는 상당히 유명한 dataset인 CIFAR-10으로 구조를 평가합니다. 32x32의 pixel image input을 가지고 아래와 같이 3x3 convolutional layer의 개수를 분포하여 구조를 설계합니다.
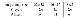
이후 마지막에 10-way fully connected layer를 놓아 총 6n+2개의 layer를 가진 구조 여러개를 설계하고 성능에 대한 평가를 실시합니다.

CIFAR-10 evaluation
점점 layer의 수를 늘려가면서 error를 측정했고, 그 결과 원하는 대로 degradation problem을 해결하여 layer의 수가 증가함에 따라서 error가 감소했습니다. 논문에서는 1202개의 layer에 대해서도 실험을 하는데, 이 경우는 overfitting의 문제로 error가 증가한 것으로 보고 있습니다.
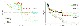
PlainNet VS ResNet
마찬가지로, 이 결과는 iteration에 따른 error의 그래프에서도 관찰할 수 있었습니다. PlainNet은 layer가 많을 수록 error가 컸지만, ResNet은 layer가 많을 수록 error가 작음을 보였습니다.
더불어 논문에서는 batch normalization 이후, 그리고 activation이전의 값들인 response에 대한 그래프를 layer index에 대해 표현한 내용을 제시했습니다.

response by layer index
위 그림을 통해 plain보다는 residual을 사용한 경우가 response가 작은 것을 확인할 수 있었고, 이는 이미 shortcut 항목을 포함한 residual의 경우가 optimal을 향해 가기 위해 필요한 변화량이 일반적으로 적을 것이라는 설계와 맞아떨어지는 부분인 것을 확인할 수 있었습니다.
Conclusion
이것으로 논문 “Deep Residual Learning for Image Recognition”의 내용을 간단하게 요약해보았습니다. 확실히, CVPR에 실린 논문이어서 설게와 평가 두 부분에 있어서 자세한 검증이 이루어져서인지 재미있게 읽을 수 있었던 것 같습니다.
왜 이 논문이 저렇게 많은 인용수를 가지고, semantic segmentation에 있어서 중요한 논문으로 평가받는지를 충분히 알 수 있었던 논문이었고, 이 분야에 대한 흥미를 일깨워주는 논문이었던 것 같습니다.
여기서는 다루지 않았지만 논문의 부록에서 Object Detection on PASCAL and MS COCO 관련하여 추가적으로 평가를 진행하는데 관심있는 분들은 한 번쯤 읽어보셔도 좋을 것 같습니다.
Get to know us better! Join our official channels below.
Telegram(EN) : t.me/Humanscape KakaoTalk(KR) : open.kakao.com/o/gqbUQEM Website : humanscape.io Medium : medium.com/humanscape-ico Facebook : www.facebook.com/humanscape Twitter : twitter.com/Humanscape_io Reddit : https://www.reddit.com/r/Humanscape_official Bitcointalk announcement : https://bit.ly/2rVsP4T Email : [email protected]
 가입하기
가입하기