휴먼스케이프 Software engineer Covy입니다.
본 포스트에서는 이전 포스트 selfie2anime에서 사용한 styleGAN의 초석이 되는 아키텍쳐인 GAN을 처음으로 선보인 논문에 대해서 리뷰하려고 합니다. 이전 포스트를 살펴보고 싶으신 분은 이곳을 참고하시면 좋습니다. 리뷰하려는 논문의 제목은 다음과 같습니다.
“Generative Adversarial Nets”
논문에 대한 내용을 직접 보시고 싶으신 분은 이곳을 참고하시면 좋습니다.

Main stream of GAN
Objective
논문에서 목적으로 하고 있는 것은 학습된 데이터 셋의 분포와 비슷한/동일한 양상을 보이는 데이터를 생성해내는 것입니다. 간단한 부연 설명으로, 사람의 얼굴 형태를 표현한 이미지 데이터를 학습 데이터로 사용한다고 가정해 봅시다. 이 경우에는 네트워크가 사람 얼굴 형태를 노이즈 데이터(의미 없는 값들)로부터 생성해낼 수 있는 능력을 학습한다는 것입니다.
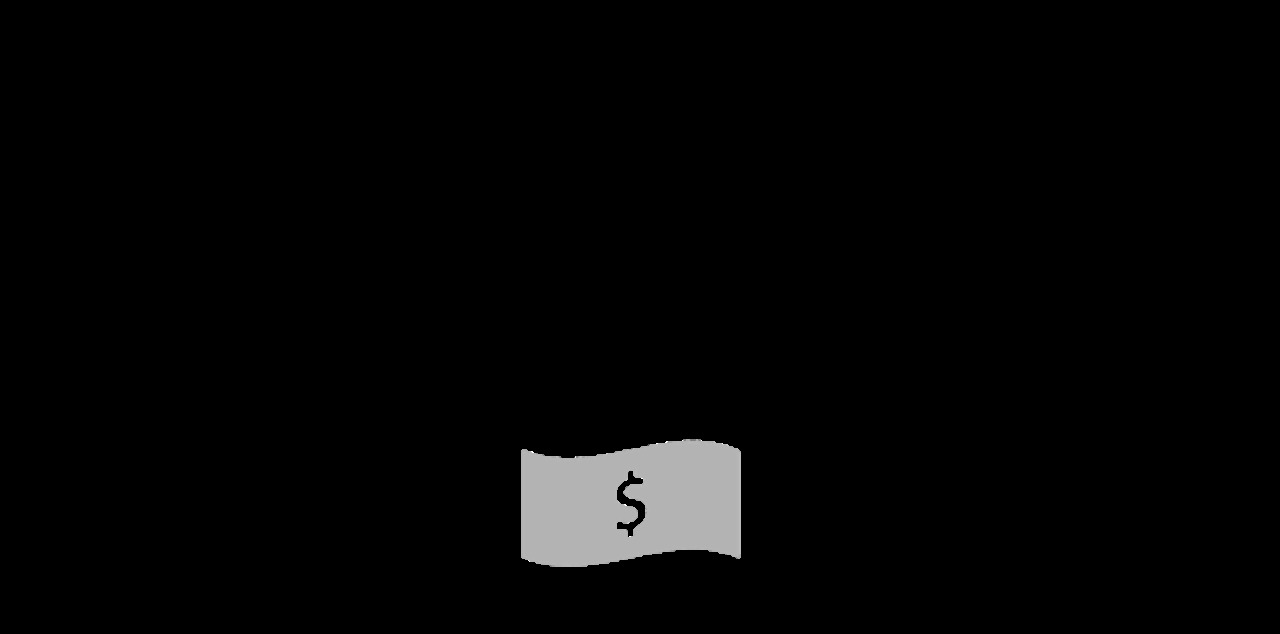
이를 달성하기 위해서 논문에서는 generator와 discriminator, 2개의 model을 경쟁적으로 학습시키는 구조를 제안합니다. 논문의 introduction에서 나온 설명을 돕기 위해서 제시한 간단한 예시는 위의 그림과 연관이 있습니다.
Generator라는 위조지폐 제작자와 discriminator라는 위조지폐 감별사가 존재하는 상황입니다. Generator는 실제 지폐랑 구별되지 않는 완벽한 위조지폐를 제작하는 것을 목표로 하고, discriminator는 그 어떤 위조지폐가 오더라도 실제 지폐와 구별해내는 것을 목표로 합니다. 이 두 사람의 목표가 서로 충돌하면서 경쟁적으로 작용하게 되고, 그들의 목표와는 별개로 위조지폐 제작자가 만들어내는 지폐가 경쟁과정에서 오히려 실제 지폐와 점점 더 가까워지게 되는 효과를 보게 되는 것입니다.
이러한 GAN은 생성모델이라는 점에서 VAE와 많이 비교가 되기도 합니다. 이 둘은 근본적으로 학습을 진행하는 것에서 차이가 있습니다. VAE는 데이터셋의 특징을 학습하여 그 특징과 variational inference를 이용하여 데이터셋을 생성해내는 반면, GAN은 이런 데이터의 분포를 추론하는 과정이 존재하지 않고 단순히 노이즈로부터 데이터를 생성해냅니다.
Adversarial Nets
앞서 설명했던 경쟁관계를 구현하기 위해서 논문에서는 adversarial nets를 설계합니다. 각각의 generator와 discriminator 모두 multilayer perceptron으로 구현합니다. 그리고 경쟁적 관계를 통한 학습효과를 나타내기 위해 아래와 같이 cost function을 정의합니다.
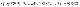
위의 식에서 p_data는 학습할 데이터의 분포를 나타내고, p_z는 input으로 들어가게 될 노이즈 데이터의 분포를 나타냅니다. D와 G는 각각 discriminator와 generator 모델의 연산과정을 의미합니다.
먼저 위의 식의 discriminator는 데이터 분포가 실제인지 생성된 것인지 결정하는 값 D(x)으로 1과 0을 산출합니다. 실제로 판단했을 경우 1로, 생성된 것으로 판단했을 경우를 0을 주게 되는 것입니다. 이러한 내용을 기반으로 아래의 내용을 살펴봅시다.
먼저, discriminator의 관점에서 위의 식을 살펴봅시다. 앞서 설명한 바와 같이 discriminator의 목표는 generator가 생성한 분포와 실제 데이터의 분포와 잘 구별해내는 것입니다. 그렇기에 x가 p_data 분포를 따르는 x에 대해서 D(x)를 1로, z가 p_z 분포를 따르는 z가 gererator 연산 G를 거쳐 나오게 된 값을 0으로 산출하여 최종 식이 최대가 되는 것을 원하게 됩니다.
다음으로 generator의 관점에서 위의 식을 살펴봅시다. 앞서 설명한 바와 같이 generator 의 목표는 discriminator가 구별하지 못하는 가짜 데이터 분포를 연산을 통해 형성해내는 것입니다. 그렇기에 z가 p_z 분포를 따르는 z가 generator 연산 G를 거쳐 나오게 된 값을 1로 산출하여 최종 식이 최소가 되는 것을 원하게 됩니다.
이 때 D에 대한 학습을 inner loop에서 많이 진행하게 되면 연산이 굉장히 복잡해지고 유한한 데이터셋에서 overfitting이 나타나는 문제가 생겼다고 합니다. 논문에서는 이를 해결할 알고리즘을 고안했는데, k번의 D에 대한 gradient descent을 적용하고 1번의 G에 대한 gradient descent를 적용하는 것이었습니다.
Learning Aspect
앞서는 adversarial net에 대해서 살펴보았습니다. 이번에는 앞서 설계한 내용이 실제로 어떤 양상으로 학습이 진행되는지에 대해서 살펴보도록 하겠습니다.
Generative adversarial nets training process
위의 그림은 논문에서 간단하게 학습이 진행되는 과정을 나타낸 그림입니다. 논문의 각 사진에서 x와 z로 적힌 선이 존재하며 그 사이를 잇는 선들을 볼 수 있습니다. 이들 변수는 각각 분포에 대한 기준이 되며, 선은 G가 z로 부터 x를 매핑하는 관계를 표현해줍니다.
그림에서 보이는 검은 점들의 분포가 실제 데이터의 분포입니다. 앞서 설명한 언어에 따르면 p_data로 볼 수 있습니다. 녹색선의분포는 생성한 데이터의 분포입니다. 앞서 설명한 언어에 따르면 G의 연산을 거친 z의 분포로 볼 수 있습니다. 마지막으로 푸른 점들의 분포는 D의 연산을 통해 구별된 정도의 분포로 볼 수 있습니다.
(a)에서 (d)로 iteration을 거쳐가면서 점점 mapping과 함께 녹색 생성 데이터가 좌측으로 편향되는 양상을 보이면서 학습 데이터와 일치하게 변하는 양상을 볼 수 있습니다. 그리고 마지막으로 갈 수록 푸른 데이터가 일정한 값을 보이게 되는데, 이는 실제와 생성된 데이터를 구별해내기 가장 어렵다고 볼 수 있는 1/2로 값이 수렴했다고 볼 수 있습니다.
Theoretical Results — Algorithm
앞에서 논문에서 설계한 알고리즘에 대해서 간략히 설명드렸었습니다. 논문에서는 이렇게 앞서 설계한 cost function과 알고리즘이 목표로하는 경쟁관계를 통해서 어떻게 학습이 진행되는지를 이론적으로 설명해줍니다.

먼저, 여기서는 알고리즘에 대해서 소개를 드리려고 합니다. 생각보다 간단한데, 그 이유가 GAN 자체가 “어떤 네트워크와 그에 특화된 적합한 알고리즘을 사용한다”가 논문의 주요 내용이 아니라, “어떤 네트워크를 사용하던 간에 논문에 적혀있는 형태의 로직을 적용하여 적대적으로 학습을 진행할 수 있다”가 주요한 내용이기 때문입니다.
앞서 소개드린 반에서 약간의 부연 설명을 진행하자면, minibatch라고 하여 모든 데이터셋을 학습에 사용하지 않고 있고, 이에 따라 stochastic gradient를 사용한다고 되어 있습니다. 그리고 k번의 D를 학습시키는 과정을 stochastic gradient로 진행합니다. 이후, G를 학습시키는 과정을 다시 한 번 진행하고 이 과정을 특정 iteration 만큼 반복하는 것입니다. 글에 적혀 있는 ascending과 descending은 각각 D를 학습시키는 과정에서는 cost function을 최대화하는 것이 목적이고, G를 학습시키는 과정에서는 cost function을 최소화하는 것이 목적인 것을 반영한 것입니다.
Theoretical Results — Validation
앞에서 논문에서 설계한 알고리즘에 대해서 간략히 설명드렸었습니다. 논문에서는 이렇게 앞서 설계한 알고리즘이 이론적으로 타당하게 원하는 목적을 달성할 수 있는지를 증명합니다. 처음으로 진행하는 것이 알고리즘을 따라서 학습했을 때 정말로 p_g를 p_data와 같게 학습할 수 있는가에 대한 것이고, 다음이 알고리즘이 정말로 수렴하는가에 대한 것입니다.

Train algorithm really works

Train algorithm really converges
위는 증명에 대한 내용을 글에서 다루기가 힘들어 정리한 내용을 사진으로 첨부한 것입니다. 아래의 convergence of algorithm에 대해서 첨언하자면, 설계한 알고리즘이 D*을 구한 후에 G에 대한 학습을 반영하는 것으로 진행되는데, 그럼에도 불구하고 이 알고리즘이 전체 cost function 최적화의 해로 수렴할 수 있는 이유를 convex function에서 찾는 내용입니다.
Experiments
논문에서는 마지막 부분에서 설계한 방법론과 알고리즘을 검증하기 위해서 MNIST, Toronto Face Database(TFD), 그리고 CIFAR-10 데이터셋에 대해서 실험을 진행합니다. 그 결과는 다음과 같습니다.

실험에 사용한 활성화 함수는 generator의 경우에는 rectifier linear과 sigmoid를 혼합해서 사용했으며, discriminator의 경우에는 maxout을 사용했다고 합니다. 더불어 D를 학습시킬 때 dropout을 사용했고, 최종적으로는 gaussian parzen window density estimation으로 평가를 진행했습니다.
결과로 보이는 바는 기존의 다른 방식 들에 비해서 눈에 띄게 큰 차이로 좋은 성능은 내는 것은 아니지만, 충분히 경쟁력이 존재한다는 점을 보여주었습니다.

(a) MNIST (b) TFD (c) CIFAR-10 (fully-connected) (d) CIFAR-10 (convolutional D, deconvolutional G)
Conclusions
이것으로 논문 “Generative Adversarial Nets”의 내용을 간단하게 요약해보았습니다. 이 논문이 세상에 등장한지 6년이 되었는데 그 사이에 GAN을 가지고 엄청나게 많은 논문들과 구현들이 나온 것을 보고 이 논문이 딥 러닝에서 얼마나 큰 영향을 준 논문인지 느낄 수 있었습니다.
주제 자체만으로도 굉장히 흥미롭고 재미있게 읽을 수 있어서 좋았던 논문이었던 것 같습니다. 특히 network에 대한 설계와 그에 대한 섬세한 평가가 이루어지는 다른 논문들과는 다르게 방법론과 알고리즘에 대한 설계와 그에 대한 이론적인 검증이 들어가는 부분이 차별적이고 신선하게 느껴졌던 것 같습니다.
여기서는 다루지 않았지만, 논문에서 future work로 발전해나갈 수 있는 사항들을 제시하는데 궁금하신 분들은 찾아보셔도 좋을 것 같습니다. 꼭 이 부분이 아니더라도 한 번 쯤은 읽어보시는 것을 추천드립니다!
Get to know us better! Join our official channels below.
Telegram(EN) : t.me/Humanscape KakaoTalk(KR) : open.kakao.com/o/gqbUQEM Website : humanscape.io Medium : medium.com/humanscape-ico Facebook : www.facebook.com/humanscape Twitter : twitter.com/Humanscape_io Reddit : https://www.reddit.com/r/Humanscape_official Bitcointalk announcement : https://bit.ly/2rVsP4T Email : [email protected]
 가입하기
가입하기