
이전 시리즈 #3 Regression에 이어 Cost function을 최소화하는 알고리즘인 Gradient Descent, 즉 경사하강법을 알아보려고 합니다. (Regression에 이어지는 시리즈이니 #3를 안보신분은 하단의 링크를 통해 보고와주세요:))
경사하강법(Gradient Descent Algorithm)은 쉽게 말해 Cost function의 기울기가 최소가 되는 값을 찾는 알고리즘입니다. 임의의 한 점에서 기울기를 구한다음, 기울어진 방향으로 계속 이동하여 Cost function이 최소가 되는 최적의 Parameters (weights)를 도출해내면 됩니다. '경사하강법' 이름 그대로, 경사(기울기)를 따라 내려가는 것과 같다고 생각하시면 됩니다.

위 그래프에서 볼 수 있듯이 경사를 따라 기울기가 작아지는 방향으로 점점 내려가는 알고리즘 입니다.
아래 식을 보며 차근차근 이해해봅시다.
#3 Regression에서 정의하였던 Cost function과 이번에 새로 공부해볼 Gradient descent algorithm 식입니다.
Gradient descent algorithm을 보면 cost function을 Θ0과 Θ1로 편미분한 것을 α(learning rate)만큼 곱해 원래의 Θ0, Θ1에서 빼주는 방식으로 동시에 업데이트 해가는 것을 알수있습니다. Θ0,와 Θ1만 고려해준 이유는 2차원으로 가정했기때문입니다. 다차원일 경우에는 더 많이 편미분 되어 업데이트에 영향을 준다고 생각하시면 됩니다. 또한 업데이트 해줄때 왜 Original값에서 편미분 값에 learning rate를 곱한 것을 빼줄까요? 아래 그림을 보면서 이해해봅시다.
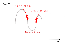
편미분(기울기)값이 -인 경우 original weigh에서 그만큼 더해주어야 global minima지역까지 하강할 수 있고, +인 경우 그만큼 빼주어야 global minima지역으로 하강할 수 있는 것입니다. 쉽게 말해 방향을 고려하기 위한 것이지요.
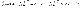
cost function을 미분하는 과정입니다.
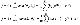
Θ0과 Θ1로 각각 편미분한 식입니다. 이것에 α를 곱해 빼주면 되겠죠?
그럼 Gradient descent algorithm에서 나온 α(learning rate)는 무엇일까요?
말그대로 학습률입니다. 경사를 따라 포인트가 내려갈 때 얼마만큼 내려갈 것 인가에 대한 내용입니다. 식 자체로 본다면 '이전의 것을 얼마나 배제하고 업데이트를 할 것 인가' 입니다. 하지만 이 learning rate에 따라 학습이 제대로 되지 않는 경우가 발생할 수 있습니다.
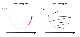
왼쪽 그래프는 learning rate가 너무 작았을 때 발생할 수 있는 내용입니다. 조금씩 내려가다보면 최저점에 내려가기 위해 더 많은 연산을 해야하고 그만큼 학습 속도가 느려진다는 단점이 있습니다.
오른쪽 그래프를 보시면 learning rate가 너무 클 때, 경사면을 타고 올라가 발산(Overshooting)해버리는 경우가 생길 수 있습니다.
Learning rate는 보통 0.01~0.001사이를 많이 사용하는데, 귀납적으로 추론해가시면 됩니다.
일반적으로 Gradient descent algroithm에는 문제가 있을 수 있는데, 초기 포인트를 어디서부터 시작하는지, 학습률 등의 여러 상황에 따라 global minimum을 찾지 못하고 local minimum을 잡을수도 있다는 것입니다.

이런 문제점을 개선하기 위해 Momentum, Adagrad, RMSprop, Adam 등 다양한 대안이 만들어졌습니다.
자세한 내용은 Ruder의 블로그에 있습니다.
지금까지 경사하강법을 알아보았으니, 이 알고리즘을 활용하는 regression 문제를 tensorflow로 풀어봅시다. 코드를 하나하나 작성하다보면 작동원리를 이해하는데 도움을 받을 수 있습니다.
먼저 tensorflow를 import 해옵니다.

regression이니 주어지는 x값과 y값이 있겠죠? x_data, y_data에 list로 넣어줍니다.

plot 하기 위해 matplotlib을 불러오고 잘 그려지는지 확인해봅시다.

uniform distribution을 따르는 -1~1사이의 난수값을 반환해 W에 지정해주고, 원소 값이 0인 b를 지정해줍니다. 또한 y에
simple linear regression을 정의해줍니다.

앞서 #3 regression 콘텐츠에서 정의했던 cost function을 그대로 재현해줍니다. 또한 경사하강법을 통해 최적화를 해주기 때문에
learning rate가 0.01인 경사하강법을 정의해줍니다.
총 20번 반복하는 과정을 거치고, 한 과정마다 그래프를 그려 잘 fitting되는지 확인합니다.

아래 차트를 보시면 cost 앞에 적혀 있는 것이 step입니다. (파이썬 range를 사용하였을때 0부터 시작하여, step 또한 0부터 시작합니다.) 또한 step이 지날수록 cost가 작아지는 것을 볼 수 있습니다. 점점 cost function이 minimize되고 있다는 것입니다.

지금까지 경사하강법(Gradient Descent algorithm)과 tensorflow를 이용하여 simple linear regression을 구현하는 것까지 알아보았습니다. 많은 도움이 되셨나요? 저희 앤트하우스와 함께 머신러닝의 기초를 단단히 잡아 봅시다:)
[머신러닝/딥러닝 시리즈]
#1 Introduction
http://blog.alphasquare.co.kr/221098813480
#2 지도학습, 비지도 학습, 강화 학습
http://blog.alphasquare.co.kr/221098817606
#3 Linear Regression(선형회귀)
http://blog.alphasquare.co.kr/221149064073
차세대 주식투자 플랫폼, 알파스퀘어에서 스마트한 주식투자를 경험해보세요!

 가입하기
가입하기



