논문 소개
CRNN paper로 알려진 Baoguang Shi 의 ‘An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition’ 에 대해 간단히 소개하려고 합니다.
[1507.05717] An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its…
Abstract: Image-based sequence recognition has been a long-standing research topic in computer vision. In this paper…arxiv.org
본 논문을 한줄로 요약하면 ‘CNN과 RNN, CTC loss를 사용하여 input으로 부터 시퀀스를 인식하는 것’ 입니다. 시퀀스를 인식하는 다양한 부분에 적용할 수 있으나 본 논문에서는 이미지로부터 텍스트 시퀀스를 추출하는 것에 대해 다루고 있습니다.
네트워크 구조
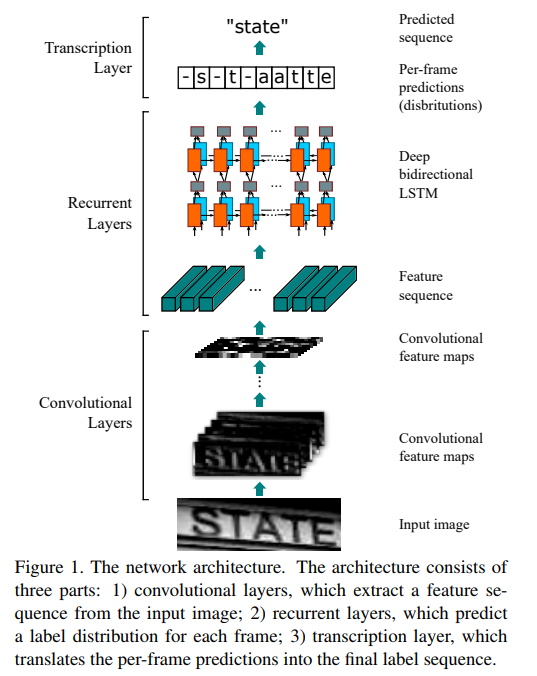
네트워크 구조
본 논문의 메인 아이디어는 위의 그림 한장으로 설명이 가능합니다. (source: https://arxiv.org/abs/1507.05717)
CNN을 통해 input 이미지로부터 feature sequence를 추출한다.
추출한 feature sequence들을 RNN의 input으로 하여 이미지의 텍스트 시퀀스를 예측한다.
예측된 텍스트 시퀀스를 텍스트로 변환한다.
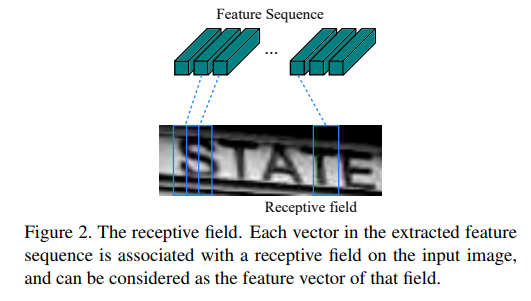
feature sequence를 RNN의 input으로 사용한다는 것이 어색할 수 있으나 아래의 그림을 보면 쉽게 이해할 수 있습니다. (source: https://arxiv.org/abs/1507.05717)

feature sequence to receptive field
각각의 feature sequence는 이미지의 특정 부분에 대한 정보를 담고 있으며 위 그림에서는 해당하는 부분에 위치하는 텍스트와 관련된 정보를 포함하고 있습니다. 텍스트에 대한 정보를 담고 있는 sequence를 통해 텍스트를 예측하기 때문에 직관적으로 CRNN이 동작함을 알 수 있습니다.
Tensorflow를 통한 구현 (pseudo code)
네트워크를 만들기 이전에 필요한 부분은 다음과 같습니다.
Prerequisite for train model
텍스트를 ctc loss의 target으로 사용할 수 있도록 텍스트 시퀀스로 변환합니다. 이 과정에서 이미지의 feature sequence의 길이를 (이미지의 width와 CNN의 stride로 결정됩니다) 고려하여 변환하는 것이 학습에 용이합니다.
Prerequisite for inference
여러 텍스트 시퀀스가 포함된 이미지일 경우 하나의 텍스트 시퀀스만 포함되도록 이미지에서 텍스트 시퀀스를 추출하는 작업이 필요합니다.
CRNN Network
def build_model(self):
print("building model...")
self.init_placeholders()
self.build_cnn()
self.build_rnn()
전체 네트워크는 placeholder와 CNN, RNN으로 구성되어 있으며 loss 계산은 build_rnn()에 포함되어 있습니다.
def build_cnn(self):
with tf.variable_scope('cnn'):
self.conv1 = activation(conv2d(self.inputs, 64,
name='conv1'))
self.pool1 = activation(conv2d(self.conv1, 64,
strides=[2, 2], name='pool1'))
self.conv2 = activation(conv2d(self.pool1, 128, name='conv2'))
self.pool2 = activation(conv2d(self.conv2, 128,
strides=[2, 2], name='pool2'))
...
self.conv7 = activation(conv2d(self.pool4, 512, name='conv7'))
shape = self.conv7.get_shape().as_list()
reshape_inputs = tf.reshape(conv7,
[self.batch_size, -1, shape[2] * shape[3]])
inputs_dense = Dense(self.hidden_units,
dtype=self.dtype, name = 'inputs_dense')
self.cnn_out = inputs_dense(reshape_inputs)
CNN의 결과로 나온 feature map을 feature sequence로 변환하여 RNN의 input으로 사용합니다.
def build_rnn(self):
self.rnn_inputs = self.cnn_out
cells_fw = [cell_type(self.hidden_units)
for _ in range(self.depth)]
cells_bw = [cell_type(self.hidden_units)
for _ in range(self.depth)]
rnn_outputs, _, _ =
tf.contrib.rnn.stack_bidirectional_dynamic_rnn(
cells_fw = cells_fw,
cells_bw = cells_bw,
inputs = self.rnn_inputs,
dtype = self.dtype,
scope='rnn1'
)
# Reshape [batch * width, hidden*2]
rnn_out_reshaped = tf.reshape(
rnn_outputs, [-1, self.hidden_units * 2])
rnn_logits = tf.layers.dense(
inputs = rnn_out_reshaped,
units = self.num_classes,
)
rnn_logits_reshaped = tf.reshape(rnn_logits,
[self.batch_size, -1, self.num_classes])
if self.mode == 'train':
self.time_major_out = tf.transpose(
rnn_logits_reshaped, [1, 0, 2], name='time_major')
self.ctc_loss = tf.nn.ctc_loss(
self.targets,
self.time_major_out,
self.seq_len,
)
self.loss = tf.reduce_mean(self.ctc_loss)
self.init_optimizer()
feature sequence를 RNN의 input으로 사용하며, RNN의 output을 target과 같은 형태가 되도록 변환한 후 target sequence와의 ctc loss가 최소화되도록 학습을 진행합니다.
Results
1000개의 class를 갖는 학습 데이터셋의 경우 12시간 정도의 학습을 통해 대부분의 텍스트를 인식할 수 있을 정도로 좋은 성능을 보였습니다. 그러나 target을 올바르게 생성하지 못하면 loss는 줄어들지만 잘못 학습된 형태로 예측하려고 하기 때문에 인식률이 올라가지 않는 경우가 있습니다. 실제로 target을 잘못 생성하여 학습을 진행하였을 때 이미지에 존재하는 텍스트를 인식하기는 하였으나, 불필요한 텍스트를 인식하는 문제가 있었습니다.
CRNN에 대한 간단한 소개 및 이를 활용하여 OCR 기술을 구현하였습니다.
잘못된 정보가 있거나 보다 자세한 정보가 필요하시면 [email protected] 으로 연락주세요.
 매스프레소(콴다)
/ 조회수 : 3863
매스프레소(콴다)
/ 조회수 : 3863