조회수 1367
[인공지능 in IT] 맥락인식, 말하지 않아도 알아요
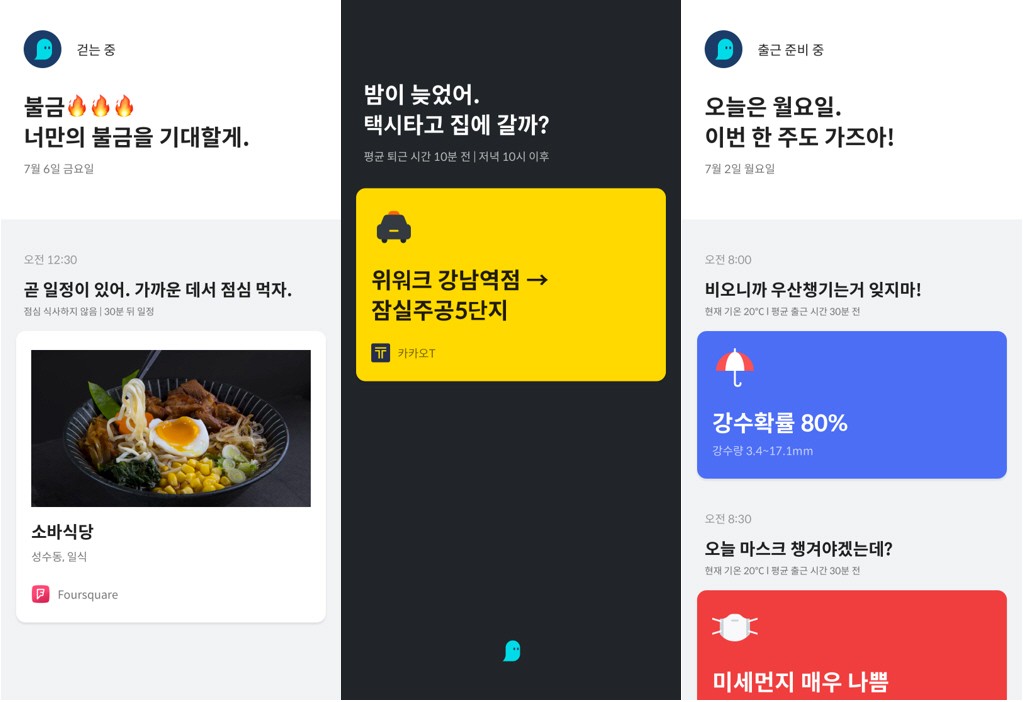
오전 6시 30분. 휴대전화 알람이 울리기 시작한다. 부랴부랴 샤워를 끝내고, 나갈 채비를 하고 있으니, 5분 후 집 앞 버스 정류장에 회사로 향하는 100번 시내버스가 도착한다는 메세지가 나타났다. 버스에 몸을 싣고 사무실 근처 정류장에 내려서 걸어가는 도중, 필자가 즐겨 마시는 커피를 맛있게 내린다는 동네 카페에 대한 정보를 받았다. 어느새 다가온 점심시간에는 어제 이태원에서 과음한 것을 어떻게 알았는지, 휴대폰 잠금화면에 주변 해장국집 추천이 뜬다.그저 영화 속 이야기가 아니다. 실제 사용자의 취향과 행동 등을 분석하고, 시간, 날씨, 교통 등과 같은 외부적 환경요소를 정교하게 더한 시나리오다. 각 개인에게 필요하고, 일상을 윤택하게 만들 수 있는 유의미한 정보를 제공하는 것. ‘맥락인식’ 혹은 ‘상황인지 기술’이라고 불리는 ‘Context Recognition’의 궁극적인 목표 중 하나다.맥락인식 기술은 여러 센서로부터 수집한 데이터를 통해 사용자의 상황을 인지하고, 실시간으로 맥락을 이해하는 데 초점을 맞춘다. GPS, 와이파이, RFID, 모션 센서, 소리 등 여러 시그널을 수집해 분석하며, 사용자의 일정, 문자 메시지나 행동 정보 등을 가져와 ‘사용자가 어떤 사람인지’, 그리고 ‘현재 어떤 상황인지’ 등을 추론한다. 이와 같은 맥락인식 기술을 구현하기 위해 필요한 몇 가지 주요기술은 다음과 같다.1. 상황정보 수집사용자 인터페이스 또는 센서, 센서 네트워크 등를 통해 사용자의 위치, 활동, 생활 패턴 등 다양하고 복잡한 정보를 수집하는 기술.2. 상황정보 모델링상황정보를 가공, 저장 및 공유하는 모델링 기술.3. 상황정보 융합 및 추론사용자의 상황정보를 다른 기술과 융합해 높은 수준의 추론 기능을 제공하는 기술.4. 상황정보 교환센서, 장치 및 객체와의 상호작용을 지원하기 위해 이벤트 기반의 통신 메커니즘을 제공하는 기술.5. 지능형 에이전트사용자의 단순한 의도뿐만 아니라 감정이나 감성을 고려해 전체 상황을 자율적으로 판단, 사용자에게 적합한 서비스를 제공하는 기술.기업 입장에서 생각했을 때, 맥락인식 기술은 소비자 개인에게 특화된 서비스를 제공할 수 있는 날카로운 검이다. 간단한 예로 맥락인식을 활용한 맞춤형 광고에 대해 알아보자. 소비자 A와 소비자 B는 서울에 사는 30대 남성이고 스포츠를 좋아한다. 일반적인 검색이나 구매 히스토리에 기반한 광고와 달리 맥락인식 기술을 활용하면, 이들의 라이프스타일이나 행동패턴을 바탕으로 더 깊은 디멘션까지 분석해 세분화된 광고를 제공할 수 있다. 두 소비자 모두 스포츠를 좋아한다고 가정했을 때, A는 한강 근처에서 매일 저녁 7시 정도에 조깅하는 것을 좋아할 수 있고, B는 남산에서 새벽 6시부터 등산하는 것을 좋아할 수 있다. 미묘한 차이겠지만, 분명 다른 카테고리의 소비자로 정의할 수 있는 것이다.스켈터랩스에서 진행하고 있는 맥락인식 기술 프로젝트를 예로 들어보자. 앞서 언급한 것처럼 다양한 기기로부터 측정하는 저레벨 데이터를 수집하는 것으로 맥락인식 프로세스는 시작된다. 측정 데이터는 서버에 전송되어 시간 순으로 변경 및 취합되고, 기계학습을 통해 필터링 후 수집되며, 고레벨의 맥락으로 추상화된다. 시간, GPS, 와이파이, 모션센서, 소리, 문자메시지, 일정 등 여러 데이터를 처리해 사용자의 맥락을 이해한다. 이러한 일련의 과정 역시 맥락인식 기술의 한 부분인지라 메시지 스트림 프로세서를 기반으로 확장할 수 있는 인프라를 설계, 구축했다.실시간으로 데이터를 처리할 수 있는 파이프라인이다. 처리한 데이터는 좀 더 상위 레벨의 이벤트와 행동으로 인식되어 ‘의미‘를 지니는 데이터로 표현되는데, 예를 들어 GPS 정보를 와이파이 및 시간 등과 같은 다른 데이터와 결합하고, 방문 장소와 행동반경 등을 포함해 사용자의 장소를 식별하는 방식이다. 이러한 사용자의 행동 히스토리는 패턴인식 기술을 활용해 사용자 특정 행동을 학습하고, 이를 기반으로 ‘언제 집으로 돌아갈지‘, 혹은 ‘언제 식사를 하는지’ 등 행동을 예측할 수 있다. 결국, 맥락인식을 통해 사용자의 다음 활동을 예측할 수 있는 기술을 개발, 사용자에게 필요하고 유용한 정보와 서비스를 제공하는 것이 목표다.< 맥락인식 기술을 적용한 큐 앱 화면, 출처: 스켈터랩스 한지예, 이해연 디자이너 >얼마 전, 스켈터랩스의 맥락인식 기술 프로젝트 팀은 해당 기술을 활용해 사용자들이 일상 속에서 가볍게 사용할 수 있는 서비스가 무엇일까 고민하고, ‘큐(Cue)’라는 앱을 개발했다. 큐는 사용자가 직접 명령할 필요가 없다. 큐가 먼저 사용자의 생활을 돕기 때문이다. 날씨를 예를 들면, 사용자가 날씨를 알아보기 전에 비가 올 것 같으면 우산을 챙기라 알려주고, 덥거나 미세먼지가 많을 경우 도움 되는 정보를 알려준다. 사용자에게 전달하는 정보는 카드 메시지를 통해 잠금화면으로 표시된다.큐 프로젝트의 이민학 시니어 프로덕트 매니저는 큐를 통해 사용자가 ‘내'가 누구인지 파악할 수 있을 것이라고 말한다. 예를 들어, 나는 내가 운동을 좋아하는 액티브한 라이프스타일을 살고 있는 줄 알았는데, 실제로는 집에 누워서 영화보는 것을 더 좋아하는 사람에 가깝다는 것. 개인의 삶이 매우 중요해지는 시대이지만, 정작 내가 누구인지 확인하기 어렵기 때문에 맥락인식 기술은 다양한 용도로 사용될 수 있다.< 사용자 패턴을 분석한 유형 결과 예시, 출처: 스켈터랩스 한지예, 이해연 디자이너 >이민학 매니저는 맥락인식 기술에 대해 이렇게 말한다. 그는 “누가, 언제, 어디서, 무엇을, 어떻게, 왜로 구성된 사용자의 육하원칙을 파악하고, 더 나아가 ‘Next-육하원칙’을 파악하는 것이 진정한 맥락인식 기술입니다. 앞으로 기업 특히, 마케터들은 타겟 고객을 잡는데 굉장히 유용하게 사용할 것이라고 생각합니다”라며, “소비자 입장에서는 일상, 문화, 생활 등 세분화된 영역에서 자신의 삶을 더 윤택하게 영위할 수 있습니다. 맥락인식 기술이야말로 인간에게 정말 도움될 수 있는, ‘피부에 와닿는' 인공지능 기술이 아닐까 생각합니다”라고 설명했다.이호진, 스켈터랩스 마케팅 매니저조원규 전 구글코리아 R&D총괄 사장을 주축으로 구글, 삼성, 카이스트 AI 랩 출신들로 구성된 인공지능 기술 기업 스켈터랩스에서 마케팅을 담당하고 있다#스켈터랩스 #기업문화 #인사이트 #경험공유 #조직문화 #인공지능기업 #기술기업