조회수 4515
Flask로 만들어 보는 WSGI 어플리케이션
안녕하세요. 스포카 크리에이터팀 문성원입니다. 오늘은 WSGI(Web Server Gateway Interface)어플리케이션을 직접 작성해보고, 또 이런 작성을 보다 쉽게 도와주는 프레임워크 중 하나인 Flask에 대해서 알아보겠습니다.WSGIWSGI에 대해 기억이 가물하신 분들을 위해 지난 글의 일부를 잠깐 다시 살펴보죠.이 경우 uwsgi는 일종의 어플리케이션 컨테이너(Application Container)로 동작하게 됩니다. 적재한 어플리케이션을 실행만 시켜주는 역할이죠. 이러한 uwsgi에 적재할 어플리케이션(스포카 서버)에는 일종의 규격이 존재하는데, 이걸 WSGI라고 합니다.(정확히는 WSGI에 의해 정의된 어플리케이션을 돌릴 수 있게 설계된 컨테이너가 uwsgi라고 봐야겠지만요.) WSGI는 Python 표준(PEP-333)으로 HTTP를 통해 요청을 받아 응답하는 어플리케이션에 대한 명세로 이러한 명세를 만족시키는 클래스나 함수, (__call__을 통해 부를 수 있는)객체를 WSGI 어플리케이션이라고 합니다.글로는 감이 잘 안오신다구요? 그럼 코드를 보면서 같이 살펴봅시다. (모든 코드는 Python 2.7에서 테스트 되었습니다.)Hello World!def app(environ, start_response): response_body = 'Hello World!' status = '200 OK' response_headers = [('Content-Type', 'text/plain'), ('Content-Length', str(len(response_body)))] start_response(status, response_headers) return [response_body]view rawgistfile1.py hosted with ❤ by GitHubapp은 일반적인 Python 함수지만, 동시에 WSGI 어플리케이션이기도 합니다. environ과 start_response를 받는 함수기 때문이죠.(PEP-333) 사실은 꼭 함수일 필요도 없습니다. 다음은 위의 app과 동일한 동작을 하는 WSGI 어플리케이션입니다.class App(object): def __init__(self, environ, start_response): self.environ = environ self.start_response = start_response def __iter__(self): status = '200 OK' response_body = "Hello World!" response_headers = [('Content-Type', 'text/plain'), ('Content-Length', str(len(response_body)))] self.start_response(status, response_headers) yield response_bodyview rawgistfile1.py hosted with ❤ by GitHubApp는 Python 클래스(Class)로 environ과 start_response를 멤버 변수로 가지는데, 여기에는 약간의 트릭이 있습니다. 생성자(Constructor)인 App를 함수처럼 사용하게 하여 리턴되는 결과(실제로는 생성자를 통해 생성된 객체겠죠.)가 \_\_iter\_\_를 구현한 순회 가능한(Iterable) 값이 되게 하는 것이죠. (덤으로 이 객체는 발생자(Generator)를 돌려주게 됩니다.)그럼 이제 이 코드들을 실행하려면 어떻게 해야할까요? 그러려면 먼저 WSGI 규격에 맞게 어플리케이션을 실행시켜 줄 서버를 작성해야합니다. 하지만 다행히도 Python 2.5부터 제공되는 wsgiref.simple_server를 이용하면 간단히 테스트 해 볼 수 있습니다.(서버를 직접 작성하는 부분에 대해선 나중에 다루도록 하겠습니다.)from wsgiref.simple_server import make_serverhttpd = make_server('', 8000, app)httpd.serve_forever()view rawgistfile1.py hosted with ❤ by GitHub위 코드를 실행시킨 후에(당연히 app이나 App도 만들어져 있어야겠죠?) 웹 브라우져를 통해 localhost:8000으로 접속하면 작성한 어플리케이션의 동작을 확인할 수 있습니다.environ과 start_response테스트도 해봤으니 코드를 조금만 더 자세히 살펴봅시다. 함수 버젼의 app이나 클래스 버젼의 App모두 공통적으로 environ과 start\_response를 인자로 받아 요청을 처리하는 것을 확인할 수 있습니다. (당연한 이야기겠지만, 반드시 이름이 environ이나 start\_response일 필요는 없습니다만 편의상 이후 계속 environ과 start_response로 표기하겠습니다.)하나씩 살펴보자면, environ은 Python 딕셔너리(dictionary)로 HTTP 요청을 처리하는데 필요한 정보가 저장되어있습니다. HTTP 요청에 대한 정보는 물론, 운영체제(OS)나 WSGI 서버의 설정 등도 정의되어있지요. 다음 코드는 이러한 environ의 내용을 응답으로 주게끔 수정한 WSGI어플리케이션입니다.def dump_environ_app(environ, start_response): response_body = "\n".join(["{0}: {1}".format(k, environ[k]) for k in environ.keys()]) status = '200 OK' response_headers = [('Content-Type', 'text/plain'), ('Content-Length', str(len(response_body)))] start_response(status, response_headers) return [response_body]view rawgistfile1.py hosted with ❤ by GitHublocalhost:8000에 각종 쿼리 스트링(Query String)을 붙이거나, 브라우져를 바꿔가면서 확인해보면 출력되는 값이 바뀌는 것을 확인하실 수 있습니다.그럼 이제 start\_response를 한번 볼까요. start\_response는 일종의 콜백(Callback)으로 인터페이스는 다음과 같습니다. start_response(status, response_headers, exc_info=None)
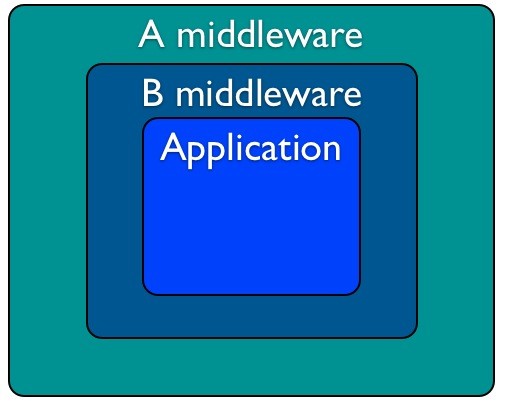
실제 서버에서 어플리케이션으로부터 응답(Response)의 상태(Status)와 헤더(Header), 그리고 예외(Exception)의 유무를 확인받아 실행하게 되는데, status와 response_headers는 HTTP 응답 명세에 근거하여 작성하게 됩니다.Middleware지금까지 우리는 어떻게 WSGI 어플리케이션을 작성하는지에 대해 살펴봤습니다. 요청을 받아 처리하는 HTTP의 기본 기능에 충실한 어플리케이션이었죠. 그런데 일반적으로 우리가 작성하는 웹 어플리케이션에서 주로 다루게 되는 쿠키(Cookie), 세션(Session)에 대해서는 어떻게 처리해야 좋을까요? WSGI 명세에는 이러한 내용을 직접적으로 다루고 있지 않습니다. WSGI 자체는 서버나 프레임워크 자체가 아니라 서버가 어플리케이션과 통신하는 명세를 다루고 있기 때문이죠. 따라서 이러한 기능은 작성자가 직접 이를 구현해야 합니다. 그런데 이런 구현을 어플리케이션을 작성할때마다 하는건 너무 번거로운 일입니다. 그것보다는 이미 작성한 어플리케이션을 확장하는 것이 간단하겠지요. 이러한 확장을 위해 필요한 것이 WSGI 미들웨어(Middleware)입니다.미들웨어는 어플리케이션을 처리하기 전후의 처리나 environ의 추가등을 통해 작성된 어플리케이션을 확장할 수 있습니다. 다음은 쿼리 스트링의 \_\_method\_\_에 따라 HTTP 메소드(Method)를 임의로 변경하는 처리를 도와주는 간단한 미들웨어입니다.from werkzeug import url_decodeclass MethodRewriteMiddleware(object): """ app = MethodRewriteMiddleware(app) """ def __init__(self, app, input_name = '__method__'): self.app = app self.input_name = input_name def __call__(self, environ, start_response): if self.input_name in environ.get('QUERY_STRING', ''): args = url_decode(environ['QUERY_STRING']) method = args.get(self.input_name) if method: method = method.encode('ascii', 'replace') environ['REQUEST_METHOD'] = method return self.app(environ, start_response)view rawgistfile1.py hosted with ❤ by GitHubMethodRewriteMiddleware는 \_\_call\_\_를 통해 app을 대체하게 됩니다. (데코레이터(Decorator)가 생각나셨다면 정확한 이해십니다.)Flask미들웨어를 통해 어플리케이션을 확장하는 방법까지 알아봤습니다. 그러나 이것만 가지고 웹 어플리케이션을 만들기에는 아직 귀찮은 부분이 많이 남아있습니다. 각종 파라미터를 처리하기 위해서는 environ를 일일히 뒤져야하며, 요청에 대한 응답으로 전달할 HTML도 일일히 문자열로 적어야하죠. 이런 여러가지 불편함을 해결하기 위해 알아볼 것이 WSGI 마이크로프레임워크를 자처하는 Flask입니다. Flask는 WSGI 라이브러리인 Werkzeug를 만들기도 한 Armin Ronacher가 만든 프레임워크로 “마이크로”라는 수식어에 어울리게 아주 핵심적인 부분만을 구현하고 있지만, 유연하게 확장이 가능하게 설계된 것이 특징입니다.다시 한번 Hello World!우선 Flask를 시스템에 설치해야하는데, pip가 설치되어있다면 pip install flask로 설치 가능합니다.(환경에 따라 루트(root)권한이 필요할 수도 있습니다.) easy_install의 경우도 마찬가지로 easy\_install flask로 설치 가능합니다.설치가 완료되었으면 다음과 같이 아주 간단한 어플리케이션을 작성해봅시다.from flask import Flaskapp = Flask(__name__)@app.route("/")def hello(): return "Hello World!"if __name__ == "__main__": app.run()view rawgistfile1.py hosted with ❤ by GitHubFlask(정확히는 Werkzeug)는 테스트를 위해 간단한 WSGI 서버를 자체 내장하고 있기 때문에 app.run을 통해 어플리케이션을 직접 실행할 수 있습니다.Route이번에 작성한 Flask 어플리케이션에는 이전까지 보지 못하던 개념이 들어 있습니다. app.route가 바로 그것인데요. 이 메서드는 URL 규칙을 받아 해당하는 규칙의 URL로 요청이 들어온 경우 등록한 함수를 실행하게끔 설정합니다. 위의 Hello World! 예제 같은 경우엔 “/”가 해당되겠지요. 또한 이런 규칙을 URL로 부터 변수도 넘겨 받을 수 있습니다.# http://flask.pocoo.org/docs/api/#[email protected]('/')def index(): [email protected]('/')def show_user(username): [email protected]('/post/')def show_post(post_id): passview rawgistfile1.py hosted with ❤ by GitHub이렇게 URL을 통해 처리할 핸들러를 찾는 것을 일반적으로 URL 라우팅(Routing)이라고 합니다. 이런 URL 라우팅에서 중요한 기능 중 하나가 핸들러에서 해당하는 URL을 생성하는 기능인데, Flask는 이를 url_for 메서드를 통해 지원합니다[email protected]('/')def index(): return ""@app.route('/')def show_user(username): return [email protected]('/post/')def show_post(post_id): return str(post_id)from flask import [email protected]("/routes")def routes(): return "".join([ url_for("index"), url_for("show_user", username="longfin"), url_for("show_post", post_id=3) ])view rawgistfile1.py hosted with ❤ by GitHub보다 자세한 사항은 API 문서를 참고하실 수 있습니다.Template여태까지 우리는 요청에 대한 응답으로 단순한 문자열을 사용했습니다. 하지만 일반적인 웹 어플리케이션의 응답은 대부분이 그것보다 훨씬 복잡하지요. 이를 보다 쉽게 작성할 수 있게끔 도와주는 것이 바로 Flask의 템플릿(Template)입니다. Flask는 기본 템플릿 엔진으로 (역시 Armin Ronacher가 작성한)Jinja2를 사용합니다.기본적으로 템플릿엔진은 별도의 규칙(여기서는 Jinja2)에 맞게 작성된 템플릿 파일을 읽어 환경(Context)에 맞게 적용한 결과물을 돌려주는데 이 과정을 Flask에서는 render_template()가 담당하고 있습니다. 다음 코드는 hello.html이라는 템플릿 파일을 읽어서 이름을 적용한 뒤에 돌려주는 코드입니다.# from http://flask.pocoo.org/docs/quickstart/#rendering-templatesfrom flask import [email protected]('/hello/')@app.route('/hello/')def hello(name=None): return render_template('hello.html', name=name)view rawgistfile1.py hosted with ❤ by GitHub쉽게 작성할 수 있게 도와준다고 해도, 템플릿 역시 나름의 학습을 필요로 합니다. 자세한 사항은 Jinja2의 API 문서를 참고하시기 바랍니다.RequestHTTP 요청을 다루기 위해서 때로는 environ의 내용은 너무 원시적일때가 있습니다. HTML 폼(Form)으로부터 입력받는 값이 좋은 예인데요. Flask에서는 request라는 객체(역시 Werkzeug에서 가져다가쓰는 거지만요)를 통해 이를 보다 다루기 쉽게 해줍니다. 다음은 HTML 폼으로부터 입력받은 message라는 값을 뒤집어서 출력하는 코드입니다.from flask import [email protected]("/reverse")def reverse(): message = request.values["message"] return "".join(reversed(message))view rawgistfile1.py hosted with ❤ by GitHubSession로그인등으로 대표되는 요청간의 상태를 유지해야하는 처리에 흔히 세션(Session)을 사용하실 겁니다. Flask에서는 session객체를 지원합니다.# from http://flask.pocoo.org/docs/quickstart/#sessionsfrom flask import Flask, session, redirect, url_for, escape, requestapp = Flask(__name__)@app.route('/')def index(): if 'username' in session: return 'Logged in as %s' % escape(session['username']) return 'You are not logged in'@app.route('/login', methods=['GET', 'POST'])def login(): if request.method == 'POST': session['username'] = request.form['username'] return redirect(url_for('index')) return ''' <form action="" method="post"> <input type=text name=username> <input type=submit value=Login> </form> '''@app.route('/logout')def logout(): # remove the username from the session if its there session.pop('username', None) return redirect(url_for('index'))# set the secret key. keep this really secret:app.secret_key = 'A0Zr98j/3yX R~XHH!jmN]LWX/,?RT'view rawgistfile1.py hosted with ❤ by GitHubFlask는 기본적으로 시큐어 쿠키(Secure Cookie)를 통해 세션을 구현하므로 길이에 제한이 있습니다. 때문에 파일이나 DB기반의 세션을 구현하려면 Beaker와 같은 프레임워크를 통한 확장이 필요합니다.(하지만 이 또한 매우 쉽습니다.)#스포카 #개발 #개발자 #개발팀 #인사이트 #기술스택 #꿀팁 #Flask